Design Evaluation and Power Study

In general, there are three stages in applying design of experiments (DOE) to solve an issue: designing the experiment, conducting the experiment, and analyzing the data. The first stage is very critical. If the designed experiment is not efficient, you are unlikely to obtain good results. It is very common to evaluate an experiment before conducting the tests. A design evaluation often focuses on the following four properties:
- The alias structure. Are main effects and two-way interactions in the experiment aliased with each other? What is the resolution of the design?
- The orthogonality. An orthogonal design is always preferred. If a design is non-orthogonal, how are the estimated coefficients correlated?
- The optimality. A design is called “optimal” if it can meet one or more of the following criteria:
- D-optimality: minimize the determinant of the variance-covariance matrix.
- A-optimality: minimize the trace of the variance-covariance matrix.
- V-optimality: minimize the average prediction variance in the design space.
- The power (or its inverse, Type II error). Power is the probability of detecting an effect through experiments when it is indeed active. A design with low power for main effects is not a good design.
In the following sections, we will discuss how to evaluate a design according to these four properties.
Alias Structure
To reduce the sample size in an experiment, we usually focus only on the main effects and lower-order interactions, while assuming that higher-order interactions are not active. For example, screening experiments are often conducted with a number of runs that barely fits the main effect-only model. However, due to the limited number of runs, the estimated main effects often are actually combined effects of main effects and interaction effects. In other words the estimated main effects are aliased with interaction effects. Since these effects are aliased, the estimated main effects are said to be biased. If the interaction effects are large, then the bias will be significant. Thus, it is very important to find out how all the effects in an experiment are aliased with each other. A design's alias structure is used for this purpose, and its calculation is given below.
Assume the matrix representation of the true model for an experiment is:
- [math]\displaystyle{ Y={{X}_{1}}{{\beta }_{1}}+{{X}_{2}}{{\beta }_{2}}+\varepsilon \,\! }[/math]
If the model used in a screening experiment is a reduced one, as given by:
- [math]\displaystyle{ Y={{X}_{1}}{{\beta }_{1}}+\varepsilon \,\! }[/math]
then, from this experiment, the estimated [math]\displaystyle{ {{\beta }_{1}}\,\! }[/math] is biased. This is because the ordinary least square estimator of [math]\displaystyle{ {{\beta }_{1}}\,\! }[/math] is:
- [math]\displaystyle{ {{\hat{\beta }}_{1}}={{\left( X_{1}^{'}{{X}_{1}} \right)}^{-1}}X_{1}^{'}Y\,\! }[/math]
As discussed in [Wu, 2000], the expected value of this estimator is:
- [math]\displaystyle{ \begin{align} & E\left( {{{\hat{\beta }}}_{1}} \right)=E\left[ {{\left( X_{1}^{'}{{X}_{1}} \right)}^{-1}}X_{1}^{'}Y \right] \\ & ={{\left( X_{1}^{'}{{X}_{1}} \right)}^{-1}}X_{1}^{'}E(Y) \\ & ={{\left( X_{1}^{'}{{X}_{1}} \right)}^{-1}}X_{1}^{'}E({{X}_{1}}{{\beta }_{1}}+{{X}_{2}}{{\beta }_{2}}+\varepsilon ) \\ & ={{\left( X_{1}^{'}{{X}_{1}} \right)}^{-1}}X_{1}^{'}{{X}_{1}}{{\beta }_{1}}+{{\left( X_{1}^{'}{{X}_{1}} \right)}^{-1}}X_{1}^{'}{{X}_{2}}{{\beta }_{2}} \\ & ={{\beta }_{1}}+A{{\beta }_{2}} \end{align}\,\! }[/math]
where [math]\displaystyle{ A={{\left( X_{1}^{'}{{X}_{1}} \right)}^{-1}}X_{1}^{'}{{X}_{2}}\,\! }[/math] is called the alias matrix of the design. For example, for a three factorial screening experiment with four runs, the design matrix is:
A B C -1 -1 1 1 -1 -1 -1 1 -1 1 1 1
If we assume the true model is:
- [math]\displaystyle{ Y={{\beta }_{0}}+{{\beta }_{1}}A+{{\beta }_{2}}B+{{\beta }_{3}}C+{{\beta }_{12}}AB+{{\beta }_{13}}AC+{{\beta }_{23}}BC+{{\beta }_{123}}ABC+\varepsilon \,\! }[/math]
and the used model (i.e., the model used in the experiment data analysis) is:
- [math]\displaystyle{ Y={{\beta }_{0}}+{{\beta }_{1}}A+{{\beta }_{2}}B+{{\beta }_{3}}C+\varepsilon \,\! }[/math]
then [math]\displaystyle{ {{X}_{1}}=[I\text{ }A\text{ }B\text{ }C]\,\! }[/math] and
[math]\displaystyle{ {{X}_{2}}=[AB\text{ }AC\text{ }BC\text{ }ABC]\,\! }[/math]. The alias matrix A is calculated as:
AB AC BC ABC I 0 0 0 1 A 0 0 1 0 B 0 1 0 0 C 1 0 0 0
Sometimes, we also put [math]\displaystyle{ {{X}_{1}}\,\! }[/math] in the above matrix. Then the A matrix becomes:
I A B C AB AC BC ABC I 1 0 0 0 0 0 0 1 A 0 1 0 0 0 0 1 0 B 0 0 1 0 0 1 0 0 C 0 0 0 1 1 0 0 0
For the terms included in the used model, the alias structure is:
[math]\displaystyle{ \begin{align}
& [I]=I+ABC \\
& [A]=A+BC \\
& [B]=B+AC \\
& [C]=C+AB \\
\end{align}\,\! }[/math]
From the alias structure and the definition of resolution, we know this is a resolution III design. The estimated main effects are aliased with two-way interactions. For example, A is aliased with BC. If, based on engineering knowledge, the experimenter suspects that some of the interactions are important, then this design is unacceptable since it cannot distinguish the main effect from important interaction effects.
For a designed experiment it is better to check its alias structure before conducting the experiment to determine whether or not some of the important effects can be clearly estimated.
Orthogonality
Orthogonality is a model-related property. For example, for a main effect-only model, if all the coefficients estimated through ordinary least squares estimation are not correlated, then this experiment is an orthogonal design for main effects. An orthogonal design has the minimal variance for the estimated model coefficients. Determining whether a design is orthogonal is very simple. Consider the following model:
- [math]\displaystyle{ Y=X\beta +\varepsilon \,\! }[/math]
The variance and covariance matrix for the model coefficients is:
- [math]\displaystyle{ Var\left( {\hat{\beta }} \right)=\sigma _{\varepsilon }^{2}{{\left( {{X}^{'}}X \right)}^{-1}}\,\! }[/math]
where [math]\displaystyle{ \sigma _{\varepsilon }^{2}\,\! }[/math] is the variance of the error. When all the factors in the model are quantitative factors or all the factors are 2 levels, [math]\displaystyle{ Var\left( {\hat{\beta }} \right)\,\! }[/math] is a regular symmetric matrix . The diagonal elements of it are the variances of model coefficients, and the off-diagonal elements are the covariance among these coefficients. When some of the factors are qualitative factors with more than 2 levels,
[math]\displaystyle{ Var\left( {\hat{\beta }} \right)\,\! }[/math] is a block symmetric matrix. The block elements in the diagonal represent the variance and covariance matrix of the qualitative factors, and the off-diagonal elements are the covariance among all the coefficients.
Therefore, to check if a design is orthogonal for a given model, we only need to check matrix :[math]\displaystyle{ {{\left( {{X}^{'}}X \right)}^{-1}}\,\! }[/math]. For the example used in the previous section, if we assume the main effect-only model is used, then [math]\displaystyle{ {{\left( {{X}^{'}}X \right)}^{-1}}\,\! }[/math] is:
I A B C I 0.25 0 0 0 A 0 0.25 0 0 B 0 0 0.25 0 C 0 0 0 0.25
Since all the off-diagonal elements are 0, the design is an orthogonal design for main effects. For an orthogonal design, it is also true that the diagonal elements are 1/n, where n is the number of total runs.
When there are qualitative factors with more than 2 levels in the model, [math]\displaystyle{ {{\left( {{X}^{'}}X \right)}^{-1}}\,\! }[/math] will be a block symmetric matrix. For example, assume we have the following design matrix.
Run Order A B 1 -1 1 2 -1 1 3 -1 1 4 -1 2 5 -1 2 6 -1 2 7 -1 3 8 -1 3 9 -1 3 10 1 1 11 1 1 12 1 1 13 1 2 14 1 2 15 1 2 16 1 3 17 1 3 18 1 3
Factor B has 3 levels, so 2 indicator variables are used in the regression model. The [math]\displaystyle{ {{\left( {{X}^{'}}X \right)}^{-1}}\,\! }[/math] matrix for a model with main effects and the interaction is:
I A B[1] B[2] AB[1] AB[2] I 0.0556 0 0 0 0 0 A 0 0.0556 0 0 0 0 B[1] 0 0 0.1111 -0.0556 0 0 B[2] 0 0 -0.0556 0.1111 0 0 AB[1] 0 0 0 0 0.1111 -0.0556 AB[2] 0 0 0 0 -0.0556 0.1111
The above matrix shows this design is orthogonal since it is a block diagonal matrix.
For an orthogonal design for a given model, all the coefficients in the model can be estimated independently. Dropping one or more terms from the model will not affect the estimation of other coefficients and their variances. If a design is not orthogonal, it means some of the terms in the model are correlated. If the correlation is strong, then the statistical test results for these terms may not be accurate.
VIF (variance inflation factor) is used to examine the correlation of one term with other terms. The VIF is commonly used to diagnose multicollinearity in regression analysis. As a rule of thumb, a VIF of greater than 10 indicates a strong correlation between some of the terms. VIF can be simply calculated by:
- [math]\displaystyle{ VI{{F}_{i}}=\frac{n}{{{\sigma }^{2}}}\operatorname{var}\left( {{{\hat{\beta }}}_{i}} \right)\,\! }[/math]
For more detailed discussion on VIF, please see Multiple Linear Regression Analysis.
Optimality
Orthogonal design is always ideal. However, due to the constraints on sample size and cost, it is sometimes not possible. If this is the case, we want to get a design that is as orthogonal as possible. The so-called D-efficiency is used to measure the orthogonality of a two level factorial design. It is defined as:
- D-efficiency[math]\displaystyle{ ={{\left( \frac{\left| X'X \right|}{{{n}^{p}}} \right)}^{1/p}}\,\! }[/math]
where p is the number of coefficients in the model and n is the total sample size. D represents the determinant.
[math]\displaystyle{ X'X\,\! }[/math] is the information matrix of a design. When you compare two different screening designs, the one with a larger determinant of [math]\displaystyle{ X'X\,\! }[/math] is usually better. D-efficiency can be used for comparing two designs. Other alphabetic optimal criteria are also used in design evaluation. If a model and the number of runs are given, an optimal design can be found using computer algorithms for one of the following optimality criteria:
- D-optimality: maximize the determinant of the information matrix [math]\displaystyle{ X'X\,\! }[/math]. This is the same as minimizing the determinant of the variance-covariance matrix [math]\displaystyle{ {{\left( X'X \right)}^{-1}}\,\! }[/math].
- A-optimality: minimize the trace of the variance-covariance matrix [math]\displaystyle{ {{\left( X'X \right)}^{-1}}\,\! }[/math]. The trace of a matrix is the sum of all its diagonal elements.
- V-optimality (or I-optimality): minimize the average prediction variance within the design space.
The determinant of [math]\displaystyle{ X'X\,\! }[/math] and the trace of [math]\displaystyle{ {{\left( X'X \right)}^{-1}}\,\! }[/math]
are given in the design evaluation in the DOE folio. V-optimality is not yet included.
Power Study
Power calculation is another very important topic in design evaluation. When designs are balanced, calculating the power (which, you will recall, is the probability of detecting an effect when that effect is active) is straightforward. However, for unbalanced designs, the calculation can be very complicated. We will discuss methods for calculating the power for a given effect for both balanced and unbalanced designs.
Power Study for Single Factor Designs (One-Way ANOVA)
Power is related to Type II error in hypothesis testing and is commonly used in statistical process control (SPC). Assume that at the normal condition, the output of a process follows a normal distribution with a mean of 10 and a standard deviation of 1.2. If the 3-sigma control limits are used and the sample size is 5, the control limits (assuming a normal distribution) for the X-bar chart are:
- [math]\displaystyle{ \begin{align} & UCL=\bar{x}+3\frac{\sigma }{\sqrt{n}}=10+3\frac{1.2}{\sqrt{5}}=11.61 \\ & LCL=\bar{x}-3\frac{\sigma }{\sqrt{n}}=10-3\frac{1.2}{\sqrt{5}}=8.39 \\ \end{align}\,\! }[/math]
If a calculated mean value from a sampling group is outside of the control limits, then the process is said to be out of control. However, since the mean value is from a random process following a normal distribution with a mean of 10 and standard derivation of
[math]\displaystyle{ {\sigma }/{\sqrt{n}}\;\,\! }[/math], even when the process is under control, the sample mean still can be out of the control limits and cause a false alarm. The probability of causing a false alarm is called Type I error (or significance level or risk level). For this example, it is:
- [math]\displaystyle{ \text{Type I Err}=2\times \left( 1-\Phi \left( 3 \right) \right)=0.0027\,\! }[/math]
Similarly, if the process mean has shifted to a new value that means the process is indeed out of control (e.g., 12), applying the above control chart, the sample mean can still be within the control limits, resulting in a failure to detect the shift. The probability of causing a misdetection is called Type II error. For this example, it is:
- [math]\displaystyle{ \begin{align} & \text{Type II Err}=\Pr \left\{ LCL\lt \bar{x}\lt UCL|\mu =12 \right\}=\Phi \left( \frac{UCL-12}{{1.2}/{\sqrt{5}}\;} \right)-\Phi \left( \frac{LCL-12}{{1.2}/{\sqrt{5}}\;} \right) \\ & =\Phi \left( -0.\text{72672} \right)-\Phi \left( -\text{6}.\text{72684} \right) \\ & =0.2337 \end{align}\,\! }[/math]
Power is defined as 1-Type II error. In this case, it is 0.766302. From this example, we can see that Type I and Type II errors are affected by sample size. Increasing sample size can reduce both errors. Engineers usually determine the sample size of a test based on the power requirement for a given effect. This is called the Power and Sample Size issue in design of experiments.
Power Calculation for Comparing Two Means
For one factor design, or one-way ANOVA, the simplest case is to design an experiment to compare the mean values at two different levels of a factor. Like the above control chart example, the calculated mean value at each level (in control and out of control) is a random variable. If the two means are different, we want to have a good chance to detect it. The difference of the two means is called the effect of this factor. For example, to compare the strength of a similar rope from two different manufacturers, 5 samples from each manufacturer are taken and tested. The test results (in newtons) are given below.
M1 M2 123 99 134 103 132 100 100 105 98 97
For this data, the ANOVA results are:
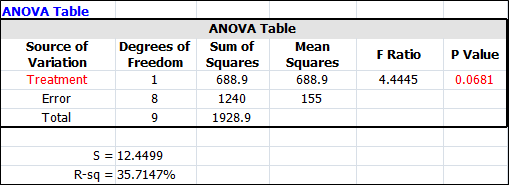
The standard deviation of the error is 12.4499 as shown in the above screenshot. and the t-test results are:
Mean Comparisons Contrast Mean Difference Pooled Standard Error Low CI High CI T Value P Value M1 - M2 16.6 7.874 -1.5575 34.7575 2.1082 0.0681
Since the p value is 0.0681, there is no significant difference between these two vendors at a significance level of 0.05 (since .0681 > 0.05). However, since the samples are randomly taken from the two populations, if the true difference between the two vendors is 30, what is the power of detecting this amount of difference from this test?
To answer this question: first, from the significance level of 0.05, let’s calculate the critical limits for the t-test. They are:
- [math]\displaystyle{ \begin{align} & L=t_{0.025,v=8}^{-1}=-2.306 \\ & U=t_{0.975,v=8}^{-1}=2.306 \\ \end{align}\,\! }[/math]
Define the mean of each vendor as
[math]\displaystyle{ {{\mu }_{i}}\,\! }[/math]
and
[math]\displaystyle{ d={{\mu }_{1}}-{{\mu }_{2}}\,\! }[/math]
. Then the difference between the estimated sample means is:
- [math]\displaystyle{ \hat{d}={{\hat{\mu }}_{1}}-{{\hat{\mu }}_{2}}\,\! }[/math]
Under the null hypothesis (the two vendors are the same), the t statistic is:
- [math]\displaystyle{ {{t}_{0}}=\frac{{{{\hat{\mu }}}_{1}}-{{{\hat{\mu }}}_{2}}}{\sqrt{\frac{{{\sigma }^{2}}}{{{n}_{1}}}+\frac{{{\sigma }^{2}}}{{{n}_{2}}}}}\,\! }[/math]
Under the alternative hypothesis when the true difference is 30, the calculated t statistic is from a non-central t distribution with non-centrality parameter [math]\displaystyle{ \delta \,\! }[/math] of:
- [math]\displaystyle{ \delta =\frac{30}{\sqrt{\frac{{{\sigma }^{2}}}{{{n}_{1}}}+\frac{{{\sigma }^{2}}}{{{n}_{2}}}}}=3.81004\,\! }[/math]
The Type II error is
[math]\displaystyle{ \Pr \left\{ L\lt {{t}_{0}}\lt U|d=30 \right\}=0.08609\,\! }[/math]
. So the power is 1-0.08609 =0.91391.
In a DOE folio, the Effect for the power calculation is entered as the multiple of the standard deviation of error. So effect of 30 is [math]\displaystyle{ 30/S=30/12.4499=\text{2}.\text{4}0\text{9658}\,\! }[/math] standard deviation. This information is illustrated below.

and the calculated power for this effect is:

As we know, the square of a t distribution is an F distribution. The above ANOVA table uses the F distribution and the above "mean comparison" table uses the t distribution to calculate the p value. The ANOVA table is especially useful when conducting multiple level comparisons. We will illustrate how to use the F distribution to calculate the power for this example.
At a significance level of 0.05, the critical value for the F distribution is:
- [math]\displaystyle{ U=f_{0.05,v1=1,v2=8}^{-1}=5.317655\,\! }[/math]
Under the alternative hypothesis when the true difference of these 2 vendors is 30, the calculated f statistic is from a non-central F distribution with non-centrality parameter
[math]\displaystyle{ \phi ={{\delta }^{2}}=14.5161\,\! }[/math].
The Type II error is [math]\displaystyle{ \Pr \left\{ f\lt U|d=30 \right\}={{F}_{v1=1,v2=8,\phi =14.5161}}\left( f\lt U \right)=0.08609\,\! }[/math]. So the power is 1-0.08609 = 0.91391. This is the same as the value we calculated using the non-central t distribution.
Power Calculation for Comparing Multiple Means: Balanced Designs
When a factor has only two levels, as in the above example, there is only one effect of this factor, which is the difference of the means at these two levels. However, when there are multiple levels, there are multiple paired comparisons. For example, if there are r levels for a factor, there are [math]\displaystyle{ \left( \begin{align} & r \\ & 2 \\ \end{align} \right)\,\! }[/math] paired comparisons. In this case, what is the power of detecting a given difference among these comparisons?
In a DOE folio, the power for a multiple level factor is defined as follows: given the largest difference among all the level means is [math]\displaystyle{ \Delta \,\! }[/math], power is the smallest probability of detecting this difference at a given significance level.
For example, if a factor has 4 levels and [math]\displaystyle{ \Delta \,\! }[/math] is 3, there are many scenarios that the largest difference among all the level means will be 3. The following table gives 4 possible scenarios.
Case M1 Μ2 M3 M4 1 24 27 25 26 2 25 25 26 23 3 25 25 25 28 4 25 25 26.5 23.5
For all 4 cases, the largest difference among the means is the same: 3. The probability of detecting
[math]\displaystyle{ \Delta =3\,\! }[/math]
(individual power) can be calculated using the method in the previous section for each case. It has been proven in [Kutner etc 2005, Guo etc 2012] that when the experiment is balanced, case 4 gives the lowest probability of detecting a given amount of effect. Therefore, the individual power calculated for case 4 is also the power for this experiment. In case 4, all but two factor level means are at the grand mean, and the two remaining factor level means are equally spaced around the grand mean. Is this a general pattern? Can the conclusion from this example be applied to general cases of balanced design?
To answer these questions, let’s illustrate the power calculation mathematically. In one factor design or one-way ANOVA, a level is also traditionally called a treatment. The following linear regression model is used to model the data:
- [math]\displaystyle{ {{Y}_{ij}}={{\beta }_{0}}+{{\beta }_{1}}{{X}_{ij1}}+{{\beta }_{2}}{{X}_{ij2}}+...+{{\beta }_{r-1}}{{X}_{ij,r-1}}+{{\varepsilon }_{ij}}\,\! }[/math]
where
[math]\displaystyle{ {{Y}_{ij}}\,\! }[/math]
is the [math]\displaystyle{ j\,\! }[/math]th observation at the [math]\displaystyle{ i\,\! }[/math]th treatment and
- [math]\displaystyle{ \begin{align} & {{X}_{ij1}}=\left\{ \begin{align} & 1\text{ if case from factor level 1} \\ & -1\text{ if case from factor level }r \\ & 0\text{ otherwise} \\ \end{align} \right. \\ & \vdots \\ & {{X}_{ij,r-1}}=\left\{ \begin{align} & 1\text{ if case from factor level }r\text{-1} \\ & -1\text{ if case from factor level }r \\ & 0\text{ otherwise} \\ \end{align} \right. \\ \end{align}\,\! }[/math]
First, let’s define the problem of power calculation.
The power calculation of an experiment can be mathematically defined as:
- [math]\displaystyle{ \begin{align} &min \text{ }P\{{{f}_{critical}}\lt F\left( 1-\alpha ;r-1,{{n}_{T}}-r \right)|\phi \} \\ &subject\text{ }to\text{ }\\ &\underset{i\ne j}{\mathop{\max }}\,\left( |{{\mu }_{i}}-{{\mu }_{j}}| \right)=\Delta ,\text{ }i,j=1,...,r\text{ } \\ \end{align}\,\! }[/math]
where [math]\displaystyle{ r\,\! }[/math] is the number of levels, [math]\displaystyle{ {{n}_{T}}\,\! }[/math] is the total samples, α is the significance level of the hypothesis testing, and [math]\displaystyle{ {{f}_{critical}}\,\! }[/math] is the critical value. The obtained minimal of the objective function in the above optimization problem is the power. The above optimization is the same as minimizing
[math]\displaystyle{ \phi \,\! }[/math], the non-centrality parameter, since all the other variables in the non-central F distribution are fixed.
Second, let’s relate the level means with the regression coefficients.
Using the regression model, the mean response at the ith factor level is:
- [math]\displaystyle{ \left\{ \begin{align} & {{\mu }_{i}}={{\beta }_{0}}+{{\beta }_{i}}\text{ for }i\lt r \\ & {{\mu }_{r}}={{\beta }_{0}}-\sum\limits_{i=1}^{r-1}{{{\beta }_{i}}\text{ for }i=r} \\ \end{align} \right.\,\! }[/math]
The difference of level means can also be defined using the
[math]\displaystyle{ \beta \,\! }[/math] values. For example, let
[math]\displaystyle{ {{\Delta }_{ij}}={{\mu }_{i}}-{{\mu }_{j}}\,\! }[/math], then:
- [math]\displaystyle{ {{\Delta }_{ij}}=\left\{ \begin{align} & \left| {{\beta }_{i}}-{{\beta }_{j}}\text{ } \right|\text{ }i\lt j,\text{ }j\ne r \\ & \left| 2{{\beta }_{i}}+\sum\limits_{l\ne i}^{{}}{{{\beta }_{l}}} \right|\text{ }i=r \\ \end{align} \right.\,\! }[/math]
Using
[math]\displaystyle{ \beta \,\! }[/math], the non-centrality parameter
[math]\displaystyle{ \phi \,\! }[/math]
can be calculated as:
- [math]\displaystyle{ \phi =\beta \Sigma _{\beta }^{-1}{{\beta }^{T}}\,\! }[/math]
where [math]\displaystyle{ \beta =\left( {{\beta }_{1}},{{\beta }_{2}},...,{{\beta }_{r-1}} \right)\,\! }[/math]
and
[math]\displaystyle{ {{\Sigma }_{\beta }}\,\! }[/math]
is the variance and covariance matrix for
[math]\displaystyle{ \beta \,\! }[/math]. When the design is balanced, we know:
- [math]\displaystyle{ \Sigma _{\beta }^{-1}=\frac{1}{{{\sigma }^{2}}}X_{\beta }^{T}{{X}_{\beta }}=\frac{1}{{{\sigma }^{2}}}\left( \begin{matrix} 2n & n & & ... & n \\ n & 2n & ... & n \\ ... & ... & ... & ... \\ n & n & ... & 2n \\ \end{matrix} \right)\,\! }[/math]
where n is the sample size at each level.
Third, let’s solve the optimization problem for balanced designs.
The power is calculated when [math]\displaystyle{ \phi \,\! }[/math] is at its minimum. Therefore, for balanced designs, the optimization issue becomes:
- [math]\displaystyle{ \min \text{ }\phi \text{=}\frac{\text{2}n}{{{\sigma }^{2}}}\left[ \sum\limits_{i=1}^{r}{\beta _{i}^{2}}+\sum\limits_{i=1}^{r}{\sum\limits_{i\ne j}^{r}{{{\beta }_{i}}{{\beta }_{j}}}} \right]\,\! }[/math]
- [math]\displaystyle{ subject\text{ }to\text{ }\,\! }[/math]
- [math]\displaystyle{ \begin{align} & \max \left\{ \underset{i\lt j,j\ne r}{\mathop{|{{\mu }_{i}}-{{\mu }_{j}}|}}\,,\text{ }\underset{i\lt r,}{\mathop{\text{ }\!\!|\!\!\text{ }{{\mu }_{i}}-{{\mu }_{r}}\text{ }\!\!|\!\!\text{ }}}\, \right\} \\ & =\max \left\{ \underset{i\lt j,j\ne r}{\mathop{|{{\beta }_{i}}-{{\beta }_{j}}|}}\,,\text{ }\!\!|\!\!\text{ }2{{\beta }_{i}}+\sum\limits_{l\ne i}^{{}}{{{\beta }_{l}}}\text{ }\!\!|\!\!\text{ } \right\}=\Delta \\ \end{align}\,\! }[/math]
The two equations in the constraint represent two cases. Without losing generality, [math]\displaystyle{ \Delta \,\! }[/math]
is set to 1 in the following discussion.
Case 1:
[math]\displaystyle{ \Delta ={{\mu }_{k}}-{{\mu }_{l}}\,\! }[/math], that is, the last level of the factor does not appear in the difference of level means.
For example, let
[math]\displaystyle{ {{\Delta }_{kl}}={{\mu }_{k}}-{{\mu }_{l}}={{\beta }_{k}}-{{\beta }_{l}}=1\,\! }[/math].
[math]\displaystyle{ k,l\ne r\,\! }[/math]. The optimal solution is
[math]\displaystyle{ {{\beta }_{k}}=0.5\,\! }[/math],
[math]\displaystyle{ {{\beta }_{l}}=-0.5\,\! }[/math],
[math]\displaystyle{ {{\beta }_{i}}=0\,\! }[/math]
for
[math]\displaystyle{ i\ne k,l\,\! }[/math]. This result means that at the optimal solution,
[math]\displaystyle{ {{\mu }_{k}}=0.5\,\! }[/math],
[math]\displaystyle{ {{\mu }_{l}}=-0.5\,\! }[/math],
[math]\displaystyle{ {{\mu }_{i}}=0\,\! }[/math],
[math]\displaystyle{ i\ne k,l\,\! }[/math].
Case 2: In this case, one level in the comparisons is the last level of the factor in the largest difference of
[math]\displaystyle{ \Delta =1\,\! }[/math].
For example, let [math]\displaystyle{ {{\Delta }_{kr}}={{\mu }_{k}}-{{\mu }_{r}}=\,\! }[/math] [math]\displaystyle{ 2{{\beta }_{k}}+\sum\limits_{l\ne i}^{{}}{{{\beta }_{l}}}=1\,\! }[/math].
The optimal solution is [math]\displaystyle{ {{\beta }_{k}}=0.5\,\! }[/math], [math]\displaystyle{ {{\beta }_{i}}=0\,\! }[/math] for [math]\displaystyle{ i\ne k\,\! }[/math]. This result means that at the optimal solution, [math]\displaystyle{ {{\mu }_{k}}=0.5\,\! }[/math], [math]\displaystyle{ {{\mu }_{r}}=-0.5\,\! }[/math], and [math]\displaystyle{ {{\mu }_{i}}=0\,\! }[/math], [math]\displaystyle{ i\ne k,r\,\! }[/math].
The proof for Case 1 and Case 2 is given in [Guo IEEM2012]. The results for Case 1 and Case 2 show that when one of the level means (adjusted by the grand mean) is
[math]\displaystyle{ \Delta/2 \,\! }[/math], another level mean is -[math]\displaystyle{ \Delta/2 \,\! }[/math] and the rest level means are 0, the calculated power is the smallest power among all the possible scenarios. This result is the same as the observation for the 4-case example given at the beginning at this section.
Let’s use the above optimization method to solve the example given in the previous section. In that example, the factor has 2 levels; the sample size is 5 at each level; the estimated [math]\displaystyle{ {{\sigma }^{2}}=155\,\! }[/math]; and [math]\displaystyle{ \Delta =30\,\! }[/math]. The regression model is:
- [math]\displaystyle{ {{Y}_{ij}}={{\beta }_{0}}+{{\beta }_{1}}{{X}_{ij1}}+{{\varepsilon }_{ij}}\,\! }[/math]
Since the sample size is 5,
[math]\displaystyle{ \Sigma _{\beta }^{-1}=\frac{2n}{{{\sigma }^{2}}}=\frac{10}{155}=0.064516\,\! }[/math]. From the above discussion, we know that when
[math]\displaystyle{ {{\beta }_{1}}=0.5\Delta \,\! }[/math], we get the minimal non-centrality parameter
[math]\displaystyle{ \phi ={{\beta }_{1}}\Sigma _{\beta }^{-1}{{\beta }_{1}}=14.51613\,\! }[/math]. This value is the same as what we got in the previous section using the non-central t and F distributions. Therefore, the method discussed in this section is a general method and can be used for cases with 2 level and multiple level factors. The previous non-central t and F distribution method is only for cases with 2 level factors.
A 4 level balanced design example
Assume an engineer wants to compare the performance of 4 different materials. Each material is a level of the factor. The sample size for each level is 15 and the standard deviation [math]\displaystyle{ \sigma \,\! }[/math] is 10. The engineer wants to calculate the power of this experiment when the largest difference among the materials is 15. If the power is less than 80%, he also wants to know what the sample size should be in order to obtain a power of 80%. Assume the significant level is 5%.
Step 1: Build the linear regression model. Since there are 4 levels, we need 3 indicator variables. The model is:
- [math]\displaystyle{ {{Y}_{ij}}={{\beta }_{0}}+{{\beta }_{1}}{{X}_{ij1}}+{{\beta }_{2}}{{X}_{ij2}}+{{\beta }_{3}}{{X}_{ij3}}+{{\varepsilon }_{ij}}\,\! }[/math]
Step 2: Since the sample size is 15 and [math]\displaystyle{ \sigma \,\! }[/math]
is 10:
- [math]\displaystyle{ \Sigma _{\beta }^{-1}=\frac{1}{{{\sigma }^{2}}}\left( \begin{matrix} 30 & 15 & 15 \\ 15 & 30 & 15 \\ 15 & 15 & 30 \\ \end{matrix} \right)=\left( \begin{matrix} 0.30 & 0.15 & 0.15 \\ 0.15 & 0.30 & 0.15 \\ 0.15 & 0.15 & 0.30 \\ \end{matrix} \right)\,\! }[/math]
Step 3: Since there are 4 levels, there are 6 paired comparisons. For each comparison, the optimal
[math]\displaystyle{ \beta \,\! }[/math]
is:
ID Paired Comparison beta1 beta2 beta3 1 Level 1- Level2 0.5 -0.5 0 2 Level 1- Level 3 0.5 0 -0.5 3 Level 1- Level 4 0.5 0 0 4 Level 2- Level 3 0 0.5 -0.5 5 Level 2- Level 4 0 0.5 0 6 Level 3- Level 4 0 0 0.5
Step 4: Calculate the non-centrality parameter for each of the 6 solutions:
- [math]\displaystyle{ \Phi =\beta \Sigma _{\beta }^{-1}\beta '{{\Delta }^{2}}=\left( \begin{matrix} 16.875 & 8.4375 & 8.4375 & -8.4375 & -8.4375 & 0 \\ {} & 16.875 & 8.4375 & 8.4375 & 0 & -8.4375 \\ {} & {} & 16.875 & 0 & 8.4375 & 8.4375 \\ {} & {} & {} & 16.875 & 8.4375 & -8.4375 \\ {} & {} & {} & {} & 16.875 & 8.4375 \\ {} & {} & {} & {} & {} & 16.875 \\ \end{matrix} \right)\,\! }[/math]
The diagonal elements are the non-centrality parameter from each paired comparison. Denoting them as [math]\displaystyle{ {{\phi }_{i}}\,\! }[/math], the power should be calculated using [math]\displaystyle{ \phi =\min \left( {{\phi }_{i}} \right)\,\! }[/math]. Since the design is balanced, we see here that all the [math]\displaystyle{ {{\phi }_{i}}\,\! }[/math] are the same.
Step 5: Calculate the critical F value.
- [math]\displaystyle{ {{f}_{critical}}=F_{3,56}^{-1}(0.05)=2.7694\,\! }[/math]
Step 6: Calculate the power for this design using the non-central F distribution.
- [math]\displaystyle{ Power=1-F_{^{3,56}}^{{}}\left( {{f}_{critical}}|\phi =16.875 \right)=0.9298\,\! }[/math]
Since the power is greater than 80%, the sample size of 15 is sufficient. Otherwise, the sample size should be increased in order to achieve the desired power requirement. The settings and results in the DOE folio are given below.


Power Calculation for Comparing Multiple Means: Unbalanced Designs
If the design is not balanced, the non-centrality parameter does not have the simple expression of [math]\displaystyle{ \phi \text{=}\frac{\text{2}n}{{{\sigma }^{2}}}\left[ \sum\limits_{i=1}^{r}{\beta _{i}^{2}}+\sum\limits_{i=1}^{r}{\sum\limits_{i\ne j}^{r}{{{\beta }_{i}}{{\beta }_{j}}}} \right]\,\! }[/math], since [math]\displaystyle{ \Sigma _{\beta }^{-1}\,\! }[/math] will not have the simpler format seen in balanced designs. The optimization thus becomes more complicated. For each paired comparison, we need to solve an optimization problem by assuming this comparison has the largest difference. For example, assuming the ith comparison [math]\displaystyle{ \Delta =\underset{i\lt j}{\mathop{|{{\mu }_{i}}-{{\mu }_{j}}|}}\,\,\! }[/math] has the largest difference, we need to solve the following problem:
- [math]\displaystyle{ \min \text{ }{{\phi }_{i}}=\beta \Sigma _{\beta }^{-1}{{\beta }^{T}}\,\! }[/math]
- [math]\displaystyle{ subject to \,\! }[/math]
- [math]\displaystyle{ \Delta =\underset{i\lt j}{\mathop{|{{\mu }_{i}}-{{\mu }_{j}}|}}\,\,\! }[/math]
- [math]\displaystyle{ and \,\! }[/math]
- [math]\displaystyle{ \left\{ \text{ }\underset{i\lt k,k\ne j}{\mathop{\text{ }\!\!|\!\!\text{ }{{\mu }_{i}}-{{\mu }_{k}}\text{ }\!\!|\!\!\text{ }}}\, \right\}\le \Delta \,\! }[/math]
In total, we need to solve [math]\displaystyle{ \left( \begin{align}
& r \\
& 2 \\
\end{align} \right)\,\! }[/math] optimization problems and use the smallest [math]\displaystyle{ \min ({{\phi }_{i}})\,\! }[/math] among all the solutions to calculate the power of the experiment. Clearly, the calculation will be very expensive.
In a DOE folio, instead of calculating the exact solution, we use the optimal [math]\displaystyle{ \beta \,\! }[/math] for a balanced design to calculate the approximated power for an unbalanced design. It can be seen that the optimal [math]\displaystyle{ \beta \,\! }[/math] for a balanced design also can satisfy all the constraints for an unbalanced design. Therefore, the approximated power is always higher than the unknown true power when the design is unbalanced.
A 3-level unbalanced design example: exact solution
Assume an engineer wants to compare the performance of three different materials. 4 samples are available for material A, 5 samples for material B and 13 samples for material C. The responses of different materials follow a normal distribution with a standard deviation of [math]\displaystyle{ \sigma =1\,\! }[/math]. The engineer is required to calculate the power of detecting difference of 1 [math]\displaystyle{ \sigma \,\! }[/math] among all the level means at a significance level of 0.05.
From the design matrix of the test, [math]\displaystyle{ {{X}^{T}}X\,\! }[/math] and [math]\displaystyle{ \Sigma _{\beta }^{-1}\,\! }[/math] are calculated as:
- [math]\displaystyle{ {{X}^{T}}X=\left( \begin{matrix} 22 & -9 & -8 \\ -9 & 17 & 13 \\ -8 & 13 & 18 \\ \end{matrix} \right)\,\! }[/math],
- [math]\displaystyle{ \Sigma _{\beta }^{-1}=\left( \begin{matrix} 13.31818 & 9.727273 \\ 9.727273 & 15.09091 \\ \end{matrix} \right)\,\! }[/math]
There are 3 paired comparisons. They are
[math]\displaystyle{ {{\mu }_{1}}-{{\mu }_{2}}\,\! }[/math], [math]\displaystyle{ {{\mu }_{1}}-{{\mu }_{3}}\,\! }[/math] and [math]\displaystyle{ {{\mu }_{2}}-{{\mu }_{3}}\,\! }[/math].
If the first comparison [math]\displaystyle{ {{\mu }_{1}}-{{\mu }_{2}}\,\! }[/math] has the largest level mean difference of 1 [math]\displaystyle{ \sigma \,\! }[/math], then the optimization problem becomes:
- [math]\displaystyle{ \begin{align} & \min \text{ }{{\phi }_{1}}=\beta \Sigma _{\beta }^{-1}{{\beta }^{T}} \\ & subject\text{ }to\text{ }{{\beta }_{1}}-{{\beta }_{2}}=1;\text{ }\left| \text{2}{{\beta }_{1}}+{{\beta }_{2}} \right|\le 1;\text{ }\left| \text{2}{{\beta }_{2}}+{{\beta }_{1}} \right|\le 1 \\ \end{align}\,\! }[/math]
The optimal solution is [math]\displaystyle{ {{\beta }_{1}}=0.51852;\text{ }{{\beta }_{2}}=-0.48148\,\! }[/math], and the optimal
[math]\displaystyle{ {{\phi }_{1}}=2.22222\,\! }[/math].
If the second comparison [math]\displaystyle{ {{\mu }_{1}}-{{\mu }_{3}}\,\! }[/math]
has the largest level mean difference, then the optimization is similar to the above problem. The optimal solution is
[math]\displaystyle{ {{\beta }_{1}}=0.588235\,\! }[/math]; [math]\displaystyle{ {{\beta }_{2}}=-0.17647\,\! }[/math] and the optimal
[math]\displaystyle{ {{\phi }_{2}}=3.058824\,\! }[/math].
If the third comparison [math]\displaystyle{ {{\mu }_{2}}-{{\mu }_{3}}\,\! }[/math]
has the largest level mean difference, then the optimal solution is
[math]\displaystyle{ {{\beta }_{1}}=-0.14815\,\! }[/math]; {{\beta }_{2}}=0.57407\,\!</math> and the optimal
[math]\displaystyle{ {{\phi }_{3}}=3.61111\,\! }[/math].
From the definition of power, we know that the power of a design should be calculated using the smallest non-centrality parameter of all possible outcomes. In this example, it is
[math]\displaystyle{ \phi =\min \left( {{\phi }_{i}} \right)=2.22222\,\! }[/math]. Since the significance level is 0.05, the critical value for the F test is
[math]\displaystyle{ {{f}_{citical}}=F_{2,19}^{-1}(0.05)=3.52189\,\! }[/math]. The power for this example is:
- [math]\displaystyle{ Power=1-{{F}_{2,19}}\left( {{f}_{critical}}|\phi =2.22222 \right)=0.2161\,\! }[/math]
A 3-level unbalanced design example: approximated solution
For the above example, we can get the approximated power by using the optimal [math]\displaystyle{ \beta \,\! }[/math] of a balanced design. If the design is balanced, the optimal solution will be:
Solution ID Paired Comparison β1 β2 1 u1-u2 0.5 -0.5 2 u1-u3 0.5 0 3 u2-u3 0 0.5
Therefore:
- [math]\displaystyle{ \text{B}=\left( \begin{matrix} 0.5 & -0.5 \\ 0.5 & 0 \\ 0 & 0.5 \\ \end{matrix} \right)\,\! }[/math]
Since the design is unbalanced, use
[math]\displaystyle{ \Sigma _{\beta }^{-1}\,\! }[/math]
from the above example to get:
- [math]\displaystyle{ \Phi =\beta \Sigma _{\beta }^{-1}\beta '{{\Delta }^{2}}=\left( \begin{matrix} 2.238636 & 0.897727 & -1.34091 \\ 0.897727 & \text{3}.\text{329545} & \text{2}.\text{431818} \\ -1.34091 & \text{2}.\text{431818} & \text{3}.\text{772727} \\ \end{matrix} \right)\,\! }[/math]
The smallest
[math]\displaystyle{ {{\phi }_{i}}\,\! }[/math]
is 2.238636. For this example, it is very close to the exact solution 2.22222 given in the previous calculation. The approximated power is:
- [math]\displaystyle{ Power=1-{{F}_{2,19}}\left( {{f}_{critical}}|\phi =2.238636 \right)=0.2174\,\! }[/math]
This result is a little larger than the exact solution of 0.2162.
In practical cases, the above method can be applied to quickly check the power of a design. If the calculated power cannot meet the required value, the true power definitely will not meet the requirement, since the calculated power using this procedure is always equal to (for balanced designs) or larger than (for unbalanced designs) the true value.
The result in the DOE folio for this example is given as:
Power Study Degrees of Freedom Power for Max Difference = 1 A:Factor 1 2 0.2174 Residual 19 -
Power Study for 2 Level Factorial Designs
For 2 level factorial designs, each factor (effect) has only one coefficient. The linear regression model is:
- [math]\displaystyle{ {{Y}_{i}}={{\beta }_{0}}+{{\beta }_{1}}{{X}_{i,1}}+{{\beta }_{2}}{{X}_{i,2}}+{{\beta }_{3}}{{X}_{i,3}}+...+{{\beta }_{12}}{{X}_{i,1}}{{X}_{i,2}}+...+{{\varepsilon }_{i}}\,\! }[/math]
The model can include main effect terms and interaction effect terms. Each
[math]\displaystyle{ {{X}_{i}}\,\! }[/math]
can be -1 (the low level) or +1 (the high level). The effect of a main effect term is defined as the difference of the mean value of Y at
[math]\displaystyle{ {{X}_{i}}=+1\,\! }[/math]
and
[math]\displaystyle{ {{X}_{i}}=-1\,\! }[/math]
. Please notice that all the factor values here are coded values. For example, the effect of
[math]\displaystyle{ {{X}_{1}}\,\! }[/math]
is defined by:
- [math]\displaystyle{ Y\left( {{X}_{1}}=1 \right)-Y\left( {{X}_{1}}=-1 \right)=2{{\beta }_{1}}\,\! }[/math]
Similarly, the effect of an interaction term is also defined as the difference of the mean values of Y at the interaction terms of +1 and -1. For example, the effect of
[math]\displaystyle{ {{X}_{1}}{{X}_{2}}\,\! }[/math]
is:
- [math]\displaystyle{ Y\left( {{X}_{1}}{{X}_{2}}=1 \right)-Y\left( {{X}_{1}}{{X}_{2}}=-1 \right)=2{{\beta }_{12}}\,\! }[/math]
Therefore, if the effect of a term that we want to calculate the power for is
[math]\displaystyle{ {{\Delta }_{i}}\,\! }[/math], then the corresponding coefficient
[math]\displaystyle{ {{\beta }_{i}}\,\! }[/math]
must be
[math]\displaystyle{ {{\Delta }_{i}}/2\,\! }[/math]
. Therefore, the non-centrality parameter for each term in the model for a 2 level factorial design can be calculated as
- [math]\displaystyle{ {{\phi }_{i}}=\frac{\beta _{i}^{2}}{Var({{\beta }_{i}})}=\frac{\Delta _{i}^{2}}{4Var({{\beta }_{i}})}\,\! }[/math]
Once
[math]\displaystyle{ {{\phi }_{i}}\,\! }[/math]
is calculated, we can use it to calculate the power. If the design is balanced, the power of terms with the same order will be the same. In other words, all the main effects have the same power and all the k-way (k=2, 3, 4, …) interactions have the same power.
Example: Due to the constraints of sample size and cost, an engineer can run only the following 13 tests for a 4 factorial design:
Run A B C D 1 1 1 1 1 2 1 1 -1 -1 3 1 -1 1 -1 4 -1 1 1 -1 5 -1 1 -1 1 6 -1 -1 1 1 7 -1 -1 -1 -1 8 0 0 0 0 9 0 0 0 0 10 0 0 0 0 11 0 0 0 0 12 0 0 0 0 13 0 0 0 0
Before doing the tests, he wants to evaluate the power for each main effect. Assume the amount of effect he wants to perform a power calculation for is 2
[math]\displaystyle{ \sigma \,\! }[/math]
. The significance level is 0.05.
Step 1: Calculate the variance and covariance matrix for the model coefficients. The main effect-only model is:
- [math]\displaystyle{ {{Y}_{i}}={{\beta }_{0}}+{{\beta }_{1}}{{A}_{i}}+{{\beta }_{2}}{{B}_{i}}+{{\beta }_{3}}{{C}_{i}}+{{\beta }_{4}}{{D}_{i}}+{{\varepsilon }_{i}}\,\! }[/math]
For this model:
- [math]\displaystyle{ Var(\beta )={{\sigma }^{2}}{{\left( X'X \right)}^{-1}}\,\! }[/math]
The value for [math]\displaystyle{ {{\left( X'X \right)}^{-1}}\,\! }[/math] is
beta0 beta1 beta2 beta3 beta4 beta0 0.083333 0.020833 -0.02083 -0.02083 0.020833 beta1 0.020833 0.161458 -0.03646 -0.03646 0.036458 beta2 -0.02083 -0.03646 0.161458 0.036458 -0.03646 beta3 -0.02083 -0.03646 0.036458 0.161458 -0.03646 beta4 0.020833 0.036458 -0.03646 -0.03646 0.161458
The diagonal elements are the variances for the coefficients.
Step 2: Calculate the non-centrality parameter for each term. In this example, all the main effect terms have the same variance, so they have the same non-centrality parameter value.
- [math]\displaystyle{ {{\phi }_{i}}=\frac{\Delta _{i}^{2}}{4Var({{\beta }_{i}})}=\frac{1}{0.161458}=6.19355\,\! }[/math]
Step 3: Calculate the critical value for the F test. It is:
- [math]\displaystyle{ {{f}_{citical}}=F_{1,8}^{-1}(0.05)=5.31766\,\! }[/math]
Step 4: Calculate the power for each main effect term. For this example, the power is the same for all of them:
- [math]\displaystyle{ Power=1-{{F}_{1,8}}\left( {{f}_{critical}}|\phi =6.19355 \right)=0.58926\,\! }[/math]
The settings and results in the DOE folio are given below.


In general, the calculated power for each term will be different for unbalanced designs. However, the above procedure can be applied for both balanced and unbalanced 2 level factorial designs.
Power Study for General Level Factorial Designs
For a quantitative factor X with more than 2 levels, its effect is defined as:
- [math]\displaystyle{ Y\left( {{X}_{i}}=1 \right)-Y\left( {{X}_{i}}=-1 \right)=2{{\beta }_{i}}\,\! }[/math]
This is the difference of the expected Y values at its defined high and low level. Therefore, a quantitative factor can always be treated as a 2 level factor mathematically, regardless of its defined number of levels. A quantitative factor has only 1 term in the regression equation.
For a qualitative factor with more than 2 levels, it has more than 1 term in the regression equation. Like in the multiple level 1 factor designs, a qualitative factor with r levels will have r-1 terms in the linear regression equation. Assume there are 2 factors in a design. Factor A has 3 levels and factor B has 3 levels, the regression equation for this design is:
- [math]\displaystyle{ \begin{align} & Y={{\beta }_{0}}+{{\beta }_{1}}A[1]+{{\beta }_{2}}A[2]+{{\beta }_{3}}B[1]+{{\beta }_{4}}B[2]+{{\beta }_{11}}A[1]B[1] \\ & +{{\beta }_{12}}A[1]B[2]+{{\beta }_{21}}A[2]B[1]+{{\beta }_{22}}A[2]B[2] \end{align}\,\! }[/math]
There are 2 regression terms for each main effect, and 4 regression terms for the interaction effect. We will use the above equation to explain how the power for the main effects and interaction effects is calculated in the DOE folio. The following balanced design is used for the calculation:
Run A B Run A B 1 1 1 14 2 2 2 1 2 15 2 3 3 1 3 16 3 1 4 2 1 17 3 2 5 2 2 18 3 3 6 2 3 19 1 1 7 3 1 20 1 2 8 3 2 21 1 3 9 3 3 22 2 1 10 1 1 23 2 2 11 1 2 24 2 3 12 1 3 25 3 1 13 2 1 26 3 2 27 3 3
Power Study for Main Effects
Let’s use factor A to show how the power is defined and calculated for the main effects. For the above design, if we ignore factor B, then it becomes a 1 factor design with 9 samples at each level. Therefore, the same linear regression model and power calculation method as discussed for 1 factor designs can be used to calculate the power for the main effects for this multiple level factorial design. Since A has 3 levels, it has 3 paired comparisons: [math]\displaystyle{ {{\Delta }_{12}}={{\mu }_{1}}-{{\mu }_{2}}\,\! }[/math]; [math]\displaystyle{ {{\Delta }_{13}}={{\mu }_{1}}-{{\mu }_{3}}\,\! }[/math] and [math]\displaystyle{ {{\Delta }_{23}}={{\mu }_{2}}-{{\mu }_{3}}\,\! }[/math]. [math]\displaystyle{ {{\mu }_{i}}\,\! }[/math] is the average of the responses at the ith level. However, these three contrasts are not independent, since [math]\displaystyle{ {{\Delta }_{12}}={{\Delta }_{13}}-{{\Delta }_{23}}\,\! }[/math]. We are interested in the largest difference among all the contrasts. Let [math]\displaystyle{ \Delta =\max ({{\Delta }_{ij}})\,\! }[/math]. Power is defined as the probability of detecting a given [math]\displaystyle{ \Delta \,\! }[/math] in an experiment. Using the linear regression equation, we get:
- [math]\displaystyle{ {{\Delta }_{12}}={{\beta }_{1}}-{{\beta }_{2}};\text{ }{{\Delta }_{13}}=2{{\beta }_{1}}+{{\beta }_{2}};\text{ }{{\Delta }_{23}}=2{{\beta }_{2}}+{{\beta }_{1}}\,\! }[/math]
Just as for the 1 factor design, we know the optimal solutions are:
[math]\displaystyle{ {{\beta }_{1}}=0.5\Delta ,{{\beta }_{2}}=-0.5\Delta \,\! }[/math]
when
[math]\displaystyle{ {{\Delta }_{12}}\,\! }[/math]
is the largest difference
[math]\displaystyle{ \Delta \,\! }[/math];
[math]\displaystyle{ {{\beta }_{1}}=0.5\Delta ,{{\beta }_{2}}=0\,\! }[/math]
when
[math]\displaystyle{ {{\Delta }_{13}}\,\! }[/math]
is the largest difference
[math]\displaystyle{ \Delta \,\! }[/math]
and
[math]\displaystyle{ {{\beta }_{1}}=0,{{\beta }_{2}}=0.5\Delta \,\! }[/math]
when
[math]\displaystyle{ {{\Delta }_{23}}\,\! }[/math]
is the largest difference
[math]\displaystyle{ \Delta \,\! }[/math]. For each of the solution, a non-centrality parameter can be calculated using
[math]\displaystyle{ \text{ }{{\phi }_{i}}=\beta \Sigma _{\beta }^{-1}{{\beta }^{T}}\,\! }[/math]. Here
[math]\displaystyle{ \beta =\left( {{\beta }_{1}},{{\beta }_{2}} \right)\,\! }[/math], and
[math]\displaystyle{ \Sigma _{\beta }^{-1}\,\! }[/math]
is the inverse of the variance and covariance matrix obtained from the linear regression model when all the terms are included.
For this example, we have the coefficient matrix for the optimal solution:
- [math]\displaystyle{ B=\Delta \left( \begin{matrix} 0.5 & -0.5 \\ 0.5 & 0 \\ 0 & 0.5 \\ \end{matrix} \right)\,\! }[/math]
The standard variance matrix
[math]\displaystyle{ {{\left( X'X \right)}^{-1}}\,\! }[/math]
for all the coefficients is:
I A[1] A[2] B[1] B[2] A[1]B[1] A[1]B[2] A[2]B[1] A[2]B[2] 0.0370 0 0 0 0 0 0 0 0 0 0.0741 -0.0370 0 0 0 0 0 0 0 -0.0370 0.0741 0 0 0 0 0 0 0 0 0 0.0741 -0.0370 0 0 0 0 0 0 0 -0.0370 0.0741 0 0 0 0 0 0 0 0 0 0.1481 -0.0741 -0.0741 0.0370 0 0 0 0 0 -0.0741 0.1481 0.0370 -0.0741 0 0 0 0 0 -0.0741 0.0370 0.1481 -0.0741 0 0 0 0 0 0.0370 -0.0741 -0.0741 0.1481
Clearly the design is balanced for all the terms since the above matrix is a block diagonal matrix.
From the above table, we know the variance and covariance matrix [math]\displaystyle{ \Sigma _{\beta }^{{}}\,\! }[/math] of A is:
- [math]\displaystyle{ \Sigma _{\beta }^{{}}={{\sigma }^{2}}\left( \begin{matrix} 0.0741 & -0.0370 \\ -0.0370 & 0.0741 \\ \end{matrix} \right)\,\! }[/math]
Its inverse
[math]\displaystyle{ \Sigma _{\beta }^{-1}\,\! }[/math]
for factor A is:
- [math]\displaystyle{ \Sigma _{\beta }^{-1}=\frac{1}{{{\sigma }^{2}}}{{\left( \begin{matrix} 0.0741 & -0.0370 \\ -0.0370 & 0.0741 \\ \end{matrix} \right)}^{-1}}=\frac{1}{{{\sigma }^{2}}}\left( \begin{matrix} 18 & 9 \\ 9 & 18 \\ \end{matrix} \right)\,\! }[/math]
Assuming that the
[math]\displaystyle{ \Delta \,\! }[/math]
we are interested in is
[math]\displaystyle{ \sigma \,\! }[/math], then the calculated non-centrality parameters are:
- [math]\displaystyle{ \Phi = \beta \Sigma _{\beta }^{-1}\beta '{{\Delta }^{2}}\,\! }[/math]
=
4.5 2.25 -2.25 2.25 4.5 2.25 -2.25 2.25 4.5
The power is calculated using the smallest value at the diagonal of the above matrix. Since the design is balanced, all the 3 non-centrality parameters are the same in this example (i.e., they are 4.5).
The critical value for the F test is:
- [math]\displaystyle{ {{f}_{citical}}=F_{2,18}^{-1}(0.05)=3.55456\,\! }[/math]
Please notice that for the F distribution, the first degree of freedom is 2 (the number of terms for factor A in the regression model) and the 2nd degree of freedom is 18 (the degrees of freedom of error).
The power for main effect A is:
- [math]\displaystyle{ Power=1-{{F}_{2,18}}\left( {{f}_{critical}}|\phi =4.5 \right)=0.397729\,\! }[/math]


If the
[math]\displaystyle{ \Delta \,\! }[/math]
we are interested in is 2
[math]\displaystyle{ \sigma \,\! }[/math], then the non-centrality parameter will be 18. The power for main effect A is:
[math]\displaystyle{ Power=1-{{F}_{2,18}}\left( {{f}_{critical}}|\phi =18 \right)=0.9457\,\! }[/math]
The power is greater for a larger [math]\displaystyle{ \Delta \,\! }[/math]. The above calculation also can be used for unbalanced designs to get the approximated power.
Power Study for Interaction Effects
First, we need to define what an “interaction effect” is. From the discussion for 2 level factorial designs, we know the interaction effect AB is defined by:
- [math]\displaystyle{ Y\left( AB=1 \right)-Y\left( AB=-1 \right)=2{{\beta }_{12}}\,\! }[/math]
It is the difference between the average response at AB=1 and AB=-1. The above equation also can be written as:
- [math]\displaystyle{ \frac{Y\left( {{A}_{1}}{{B}_{1}} \right)+Y\left( {{A}_{-1}}{{B}_{-1}} \right)}{2}-\frac{Y\left( {{A}_{-1}}{{B}_{1}} \right)+Y\left( {{A}_{1}}{{B}_{-1}} \right)}{2}\,\! }[/math]
or:
- [math]\displaystyle{ \begin{align} & \frac{Y\left( {{A}_{1}}{{B}_{1}} \right)-Y\left( {{A}_{1}}{{B}_{-1}} \right)}{2}-\frac{Y\left( {{A}_{-1}}{{B}_{1}} \right)-Y\left( {{A}_{-1}}{{B}_{-1}} \right)}{2} \\ & =\frac{\text{Effect of B at A=1}}{2}-\frac{\text{Effect of B at A=-1}}{2} \\ \end{align}\,\! }[/math]
From here we can see that the effect of AB is half of the difference of the effect of B when A is fixed at 1 and the effect of B when A is fixed at -1. Therefore, a two-way interaction effect is calculated using 4 points as shown in the above equation. This is illustrated in the following figure.

As we discussed before, a main effect is defined by two points. For example, the main effect of B at A=1 is defined by
[math]\displaystyle{ Y({{A}_{1}}{{B}_{1}})\,\! }[/math]
and
[math]\displaystyle{ Y({{A}_{1}}{{B}_{-1}})\,\! }[/math]. The above figure clearly shows that a two-way interaction effect of two-level factors is defined by the 4 vertex of a quadrilateral. How can we define the two-way interaction effects of factorials with more than two levels? For example, for the design used in the previous section, A and B are both three levels. What is the interaction effect AB? For this example, the 9 design points are shown in the following figure.

Notice that there are 9 quadrilaterals in the above figure. These 9 contrasts define the interaction effect AB. This is similar to the paired comparisons in a one factorial design with multiple levels, where a main effect is defined by a group of contrasts (or paired comparisons). For the design in the above figure, to construct a quadrilateral, we need to choose 2 levels from A and 2 levels from B. There are
[math]\displaystyle{ \left( \begin{align}
& 3 \\
& 2 \\
\end{align} \right)\times \left( \begin{align}
& 3 \\
& 2 \\
\end{align} \right)=9\,\! }[/math]
combinations. Therefore, we see the following 9 contrasts.
Contrast ID A B 1 (1, 2) (1, 2) 2 (1, 2) (1, 3) 3 (1, 2) (2, 3) 4 (1, 3) (1, 2) 5 (1, 3) (1, 3) 6 (1, 3) (2, 3) 7 (2, 3) (1, 2) 8 (2, 3) (1, 3) 9 (2, 3) (2, 3)
Let’s use the first contrast to explain the meaning of a contrast. (1, 2) in column A means the selected levels from A are 1 and 2. (1, 2) in column B means the selected levels from B are 1 and 2. They form 4 points:
[math]\displaystyle{ Y({{A}_{1}}{{B}_{1}})\,\! }[/math],
[math]\displaystyle{ Y({{A}_{1}}{{B}_{2}})\,\! }[/math],
[math]\displaystyle{ Y({{A}_{2}}{{B}_{1}})\,\! }[/math] and
[math]\displaystyle{ Y({{A}_{2}}{{B}_{2}})\,\! }[/math]. We can denote the AB effect defined by this contrast as
[math]\displaystyle{ {{\Delta }_{1}}\,\! }[/math].
- [math]\displaystyle{ \begin{align} & {{\Delta }_{1}}=\frac{Y({{A}_{1}}{{B}_{1}})+Y\left( {{A}_{2}}{{B}_{2}} \right)}{2}-\frac{Y({{A}_{1}}{{B}_{2}})+Y\left( {{A}_{2}}{{B}_{1}} \right)}{2} \\ & =\frac{Y({{A}_{1}}{{B}_{1}})-Y({{A}_{1}}{{B}_{2}})-Y\left( {{A}_{2}}{{B}_{1}} \right)+Y\left( {{A}_{2}}{{B}_{2}} \right)}{2} \end{align}\,\! }[/math]
In general, if a contrast is defined by A (i, j) and B(i’, j’), then the effect is calculated by:
- [math]\displaystyle{ {{\Delta }_{AB}}=\frac{Y({{A}_{i}}{{B}_{j}})-Y({{A}_{i}}{{B}_{j'}})-Y\left( {{A}_{i'}}{{B}_{j}} \right)+Y\left( {{A}_{i'}}{{B}_{j'}} \right)}{2}\,\! }[/math]
From the above two equations we can see that the two-way interaction effect AB is defined as the difference of the main effect of B at A = i and the main effect of B at A = j. This logic can be easily extended to three-way interactions. For example ABC can be defined as the difference of AB at C=k and AC at C=k’. Its calculation is:
- [math]\displaystyle{ \begin{align} & \Delta _{ABC}^{{}}=\frac{Y({{A}_{i}}{{B}_{j}}{{C}_{k}})-Y({{A}_{i}}{{B}_{j'}}{{C}_{k}})-Y\left( {{A}_{i'}}{{B}_{j}}{{C}_{k}} \right)+Y\left( {{A}_{i'}}{{B}_{j'}}{{C}_{k}} \right)}{4} \\ & -\frac{Y({{A}_{i}}{{B}_{j}}{{C}_{k'}})-Y({{A}_{i}}{{B}_{j'}}{{C}_{k'}})-Y\left( {{A}_{i'}}{{B}_{j}}{{C}_{k'}} \right)+Y\left( {{A}_{i'}}{{B}_{j'}}{{C}_{k'}} \right)}{4} \end{align}\,\! }[/math]
For a design with A, B, and C with 3 levels, there are [math]\displaystyle{ \left( \begin{align} & 3 \\ & 2 \\ \end{align} \right)\times \left( \begin{align} & 3 \\ & 2 \\ \end{align} \right)\times \left( \begin{align} & 3 \\ & 2 \\ \end{align} \right)=27\,\! }[/math] contrast for the three-way interaction ABC.
Similarly, the above method can be extended for higher order interactions. By now, we know the main effect and interactions for multiple level factorial designs are defined by a group of contrasts. We will discuss how the power of these effects is calculated in the following section.
The power for an effect is defined as follows: when the largest value of a contrast group for an effect is [math]\displaystyle{ \Delta \,\! }[/math], power is the smallest probability of detecting this [math]\displaystyle{ \Delta \,\! }[/math] among all the possible outcomes at a given significance level.
To calculate the power for an effect, as in the previous sections, we need to relate a contrast with model coefficients. The 9 contrasts in the above table can be expressed using model coefficients. For example:
- [math]\displaystyle{ {{\Delta }_{1}}=\frac{{{\beta }_{11}}+{{\beta }_{22}}}{2}-\frac{{{\beta }_{12}}+{{\beta }_{21}}}{2}\,\! }[/math]
If this contrast has the largest value [math]\displaystyle{ \Delta \,\! }[/math], the power is calculated from the following optimization problem:
- [math]\displaystyle{ \begin{align} & \min \text{ }{{\phi }_{1}}=\beta \Sigma _{\beta }^{-1}{{\beta }^{T}} \\ & subject\text{ }to\text{ }\frac{{{\beta }_{11}}+{{\beta }_{22}}}{2}-\frac{{{\beta }_{12}}+{{\beta }_{21}}}{2}={{\Delta }_{1}}=\Delta ;\text{ }\!\!|\!\!\text{ }{{\Delta }_{i}}|\le \Delta ,i=2,...,9 \\ \end{align}\,\! }[/math]
where
[math]\displaystyle{ \beta =\left( {{\beta }_{11}},{{\beta }_{12}},{{\beta }_{21}},{{\beta }_{22}} \right)\,\! }[/math]
, and
[math]\displaystyle{ \Sigma _{\beta }^{-1}\,\! }[/math]
is the variance and covariance matrix of
[math]\displaystyle{ \beta \,\! }[/math].
For a balanced general level factorial design such as this example, the optimal solution for the above optimization issue is:
- [math]\displaystyle{ \beta =\left( {{\beta }_{11}},{{\beta }_{12}},{{\beta }_{21}},{{\beta }_{22}} \right)=(0.5,-0.5,-0.5,0.5)\,\! }[/math]
For all the 9 contrasts, by assuming each of the contrasts has the largest value
[math]\displaystyle{ \Delta \,\! }[/math]
one by one, we can get 9 optimal solutions and 9 non-centrality parameters
[math]\displaystyle{ {{\phi }_{i}}\,\! }[/math]. The power for the interaction effect AB is calculated using the min(
[math]\displaystyle{ {{\phi }_{i}}\,\! }[/math]). The 9 optimal solutions are:
Contrast ID A B [math]\displaystyle{ {{\beta }_{11}}\,\! }[/math] [math]\displaystyle{ {{\beta }_{12}}\,\! }[/math] [math]\displaystyle{ {{\beta }_{21}}\,\! }[/math] [math]\displaystyle{ {{\beta }_{22}}\,\! }[/math] 1 (1, 2) (1, 2) 0.5 -0.5 -0.5 0.5 2 (1, 2) (1, 3) 0.5 0 -0.5 0 3 (1, 2) (2, 3) 0 0.5 0 -0.5 4 (1, 3) (1, 2) 0.5 -0.5 0 0 5 (1, 3) (1, 3) 0.5 0 0 0 6 (1, 3) (2, 3) 0 0.5 0 0 7 (2, 3) (1, 2) 0 0 0.5 -0.5 8 (2, 3) (1, 3) 0 0 0.5 0 9 (2, 3) (2, 3) 0 0 0 0.5
In the regression equation for this example, there are 4 terms for AB effect. Therefore there are 4 independent contrasts in the above table. These are contrasts 5, 6, 8, and 9. The rest of the contrasts are linear combinations of these 4 contrasts. Based on the calculation in the main effect section, we know that the standard variance matrix [math]\displaystyle{ {{\left( X'X \right)}^{-1}}\,\! }[/math] for all the coefficients is:
I A[1] A[2] B[1] B[2] A[1]B[1] A[1]B[2] A[2]B[1] A[2]B[2] 0.0370 0 0 0 0 0 0 0 0 0 0.0741 -0.0370 0 0 0 0 0 0 0 -0.0370 0.0741 0 0 0 0 0 0 0 0 0 0.0741 -0.0370 0 0 0 0 0 0 0 -0.0370 0.0741 0 0 0 0 0 0 0 0 0 0.1481 -0.0741 -0.0741 0.0370 0 0 0 0 0 -0.0741 0.1481 0.0370 -0.0741 0 0 0 0 0 -0.0741 0.0370 0.1481 -0.0741 0 0 0 0 0 0.0370 -0.0741 -0.0741 0.1481
The variance and covariance matrix [math]\displaystyle{ \Sigma _{\beta }^{{}}\,\! }[/math] of AB is:
- [math]\displaystyle{ \Sigma _{\beta }^{{}}={{\sigma }^{2}}\left( \begin{matrix} 0.1481 & -0.0741 & -0.0741 & 0.0370 \\ -0.0741 & 0.1481 & 0.0370 & -0.0741 \\ -0.0741 & 0.0370 & 0.1481 & -0.0741 \\ 0.0370 & -0.0741 & -0.0741 & 0.1481 \\ \end{matrix} \right)\,\! }[/math]
Then its inverse matrix
[math]\displaystyle{ \Sigma _{\beta }^{-1}\,\! }[/math]
is:
- [math]\displaystyle{ \Sigma _{\beta }^{-1}=\frac{1}{{{\sigma }^{2}}}{{\left( \begin{matrix} 0.1481 & -0.0741 & -0.0741 & 0.0370 \\ -0.0741 & 0.1481 & 0.0370 & -0.0741 \\ -0.0741 & 0.0370 & 0.1481 & -0.0741 \\ 0.0370 & -0.0741 & -0.0741 & 0.1481 \\ \end{matrix} \right)}^{-1}}=\frac{1}{{{\sigma }^{2}}}\left( \begin{matrix} 12.0256 & 6.0250 & 6.0250 & 3.0247 \\ 6.0250 & 12.0256 & 3.0247 & 6.0250 \\ 6.0250 & 3.0247 & 12.0256 & 6.0250 \\ 3.0247 & 6.0250 & 6.0250 & 12.0256 \\ \end{matrix} \right)\,\! }[/math]
Assuming that the
[math]\displaystyle{ \Delta \,\! }[/math]
we are interested in is
[math]\displaystyle{ \sigma \,\! }[/math]
, then the calculated non-centrality parameters for all the contrasts are the diagonal elements of the following matrix.
- [math]\displaystyle{ \Phi =\,\!\beta \Sigma _{\beta }^{-1}\beta '{{\Delta }^{2}}\,\! }[/math]
=
3.0003 1.5002 -1.5002 1.5002 0.7501 -0.7501 -1.5002 -0.7501 0.7501 1.5002 3.0003 1.5002 0.7501 1.5002 0.7501 -0.7501 -1.5002 -0.7501 1.5002 1.5002 3.0003 -0.7501 0.7501 1.5002 0.7501 -0.7501 -1.5002 1.5002 0.7501 -0.7501 3.0003 1.5002 -1.5002 1.5002 0.7501 -0.7501 0.7501 1.5002 0.7501 1.5002 3.0064 1.5062 0.7501 1.5062 0.7562 0.7501 0.7501 1.5002 -1.5002 1.5062 3.0064 -0.7501 0.7562 1.5062 1.5002 -0.7501 0.7501 1.5002 0.7501 -0.7501 3.0003 1.5002 -1.5002 0.7501 -1.5002 -0.7501 0.7501 1.5062 0.7562 1.5002 3.0064 1.5062 0.7501 -0.7501 -1.5002 -0.7501 0.7562 1.5062 -1.5002 1.5062 3.0064
The power is calculated using the smallest value at the diagonal of the above matrix (i.e., 3.0003).
The critical value for the F test is:
[math]\displaystyle{ {{f}_{citical}}=F_{4,18}^{-1}(0.05)=2.927744\,\! }[/math]
Please notice that for the F distribution, the first degree of freedom is 4 (the number of terms for effect AB in the regression model) and the 2nd degree of freedom is 18 (the degree of freedom of error).
The power for AB is:
- [math]\displaystyle{ Power=1-{{F}_{4,18}}\left( {{f}_{critical}}|\phi =3.0003 \right)=0.1957\,\! }[/math]
If the
[math]\displaystyle{ \Delta \,\! }[/math]
we are interested in is 2
[math]\displaystyle{ \sigma \,\! }[/math]
, then the non-centrality parameter will be 12.0012. The power for main effect A is:
- [math]\displaystyle{ Power=1-{{F}_{4,18}}\left( {{f}_{critical}}|\phi =12.0012 \right)=0.6784\,\! }[/math]
The power values for all the effects in the model are:
![Evaluation results for effect of 2 [math]\displaystyle{ \sigma \,\! }[/math].](/index.php/File:DesignEvluation_8.png)
For balanced designs, the above calculation gives the exact power. For unbalanced design, the above method will give the approximated power. The true power is always less than the approximated value.
This section explained how to use a group of contrasts to represent the main and interaction effects for multiple level factorial designs. Examples for main and 2nd order interactions were provided. The power calculation for higher order interactions is the same as the above example. Therefore, it is not repeated here.
Power Study for Response Surface Method Designs
For response surface method designs, the following linear regression model is used:
[math]\displaystyle{ Y={{\beta }_{0}}+{{\beta }_{1}}{{X}_{1}}+{{\beta }_{2}}{{X}_{2}}+...+{{\beta }_{11}}X_{1}^{2}+{{\beta }_{22}}X_{2}^{2}+{{\beta }_{12}}{{X}_{1}}{{X}_{2}}+...+\varepsilon \,\! }[/math]
The above equations can have both qualitative and quantitative factors. As we discussed before, for each effect (main or quadratic effect) of a quantitative factor, there is only one term in the regression model. Therefore, the power calculation for a quantitative factor is the same as treating this factor as a 2 level factor, no matter how many levels are defined for it. If qualitative factors are used in the design, they do not have quadratic effects in the model. The power calculation for qualitative factors is the same as discussed in the previous sections.
First we need to define what the “effect” is for each term in the above linear regression equation. The definition for main effects and interaction effects is the same as for 2 level factorial designs. The effect is defined as the difference of the average response at the +1 of the term and at the -1 of the term. For example, the main effect of [math]\displaystyle{ {{X}_{i}}\,\! }[/math] is:
- [math]\displaystyle{ {{\Delta }_{i}}=Y\left( {{X}_{i}}=1 \right)-Y\left( {{X}_{i}}=-1 \right)=2{{\beta }_{i}}\,\! }[/math]
The interaction effect of
[math]\displaystyle{ {{X}_{i}}{{X}_{j}}\,\! }[/math]
is:
- [math]\displaystyle{ {{\Delta }_{ij}}=Y\left( {{X}_{i}}{{X}_{j}}=1 \right)-Y\left( {{X}_{i}}{{X}_{j}}=-1 \right)=2{{\beta }_{ij}}\,\! }[/math]
For a quadratic term
[math]\displaystyle{ X_{i}^{2}\,\! }[/math], its range is from 0 to 1. Therefore, its effect is:
- [math]\displaystyle{ {{\Delta }_{ii}}=Y\left( X_{i}^{2}=1 \right)-Y\left( X_{i}^{2}=0 \right)={{\beta }_{ii}}\,\! }[/math]
The quadratic term also can be thought of as:
- [math]\displaystyle{ {{\Delta }_{ii}}=\frac{Y\left( {{X}_{i}}=1 \right)+Y\left( {{X}_{i}}=-1 \right)}{2}-Y\left( {{X}_{i}}=0 \right)={{\beta }_{ii}}\,\! }[/math]
Since there are no grouped contrasts for each effect, the power can be calculated using either the non-central t distribution or the non-central F distribution. They will lead to the same results. Let’s use the following design to illustrate the calculation.
Run Block A B C 1 1 -1 -1 -1 2 1 1 -1 -1 3 1 -1 1 -1 4 1 1 1 -1 5 1 -1 -1 1 6 1 1 -1 1 7 1 -1 1 1 8 1 1 1 1 9 1 0 0 0 10 1 0 0 0 11 1 0 0 0 12 1 0 0 0 13 2 -1.68179 0 0 14 2 1.681793 0 0 15 2 0 -1.68179 0 16 2 0 1.681793 0 17 2 0 0 -1.68179 18 2 0 0 1.681793 19 2 0 0 0 20 2 0 0 0 21 3 -1 -1 -1 22 3 1 -1 -1 23 3 -1 1 -1 24 3 1 1 -1 25 3 -1 -1 1 26 3 1 -1 1 27 3 -1 1 1 28 3 1 1 1 29 3 0 0 0 30 3 0 0 0 31 3 0 0 0 32 3 0 0 0 33 4 -1.68179 0 0 34 4 1.681793 0 0 35 4 0 -1.68179 0 36 4 0 1.681793 0 37 4 0 0 -1.68179 38 4 0 0 1.681793 39 4 0 0 0 40 4 0 0 0
The above design can be created in a DOE folio using the following settings:

The model used here is:
- [math]\displaystyle{ \begin{align} & Y={{\beta }_{0}}+{{\beta }_{b1}}BLK[1]+{{\beta }_{b2}}BLK[2]+{{\beta }_{b3}}BLK[3]+{{\beta }_{1}}A+{{\beta }_{2}}B+{{\beta }_{3}}C \\ & +{{\beta }_{12}}AB+{{\beta }_{13}}AC+{{\beta }_{23}}BC+{{\beta }_{11}}{{A}^{2}}+{{\beta }_{22}}{{B}^{2}}+{{\beta }_{33}}{{C}^{2}} \end{align}\,\! }[/math]
Blocks are included in the model. Since there are four blocks, three indicator variables are used. The standard variance and covariance matrix
[math]\displaystyle{ {{\left( X'X \right)}^{-1}}\,\! }[/math] is
Const BLK1 BLK2 BLK3 A B C AB AC BC AA BB CC 0.085018 -0.00694 0.006944 -0.00694 0 0 0 0 0 0 -0.02862 -0.02862 -0.02862 0.00694 0.067759 -0.02609 -0.01557 0 0 0 0 0 0 0.000843 0.000843 0.000843 0.006944 -0.02609 0.088593 -0.02609 0 0 0 0 0 0 -0.00084 -0.00084 -0.00084 0.00694 -0.01557 -0.02609 0.067759 0 0 0 0 0 0 0.000843 0.000843 0.000843 0 0 0 0 0.036612 0 0 0 0 0 0 0 0 0 0 0 0 0 0.036612 0 0 0 0 0 0 0 0 0 0 0 0 0 0.036612 0 0 0 0 0 0 0 0 0 0 0 0 0 0.0625 0 0 0 0 0 0 0 0 0 0 0 0 0 0.0625 0 0 0 0 0 0 0 0 0 0 0 0 0 0.0625 0 0 0 0.02862 0.000843 -0.00084 0.000843 0 0 0 0 0 0 0.034722 0.003472 0.003472 0.02862 0.000843 -0.00084 0.000843 0 0 0 0 0 0 0.003472 0.034722 0.003472
The variances for all the coefficients are the diagonal elements in the above matrix. These are:
Term Var([math]\displaystyle{ {{\sigma }^{2}}\,\! }[/math]) A 0.036612 B 0.036612 C 0.036612 AB 0.0625 AC 0.0625 BC 0.0625 AA 0.034722 BB 0.034722 CC 0.034722
Assume the value for each effect we are interested in is [math]\displaystyle{ \Delta \,\! }[/math] . Then, to get this [math]\displaystyle{ \Delta \,\! }[/math] the corresponding value for each model coefficient is:
Term Coefficient A 0.5[math]\displaystyle{ \Delta \,\! }[/math] B 0.5[math]\displaystyle{ \Delta \,\! }[/math] C 0.5[math]\displaystyle{ \Delta \,\! }[/math] AB 0.5[math]\displaystyle{ \Delta \,\! }[/math] AC 0.5[math]\displaystyle{ \Delta \,\! }[/math] BC 0.5[math]\displaystyle{ \Delta \,\! }[/math] AA 1[math]\displaystyle{ \Delta \,\! }[/math] BB 1[math]\displaystyle{ \Delta \,\! }[/math] CC 1[math]\displaystyle{ \Delta \,\! }[/math]
The degrees of freedom used in the calculation are:
Source Degree of Freedom Block 3 A:A 1 B:B 1 C:C 1 AB 1 AC 1 BC 1 AA 1 BB 1 CC 1 Residual 27 Lack of Fit 19 Pure Error 8 Total 39
The above table shows all the factor effects have the same degree of freedom, therefore they have the same critical F value. For a significance level of 0.05, the critical value is:
- [math]\displaystyle{ {{f}_{citical}}=F_{1,27}^{-1}(0.05)=4.210008\,\! }[/math]
When
[math]\displaystyle{ \Delta =1\sigma \,\! }[/math]
, the non-centrality parameter for each main effect is calculated by:
- [math]\displaystyle{ {{\phi }_{i}}=\frac{\beta _{i}^{2}}{Var\left( {{\beta }_{i}} \right)}=\frac{{{\left( 0.5\Delta \right)}^{2}}}{Var\left( {{\beta }_{i}} \right)}=\frac{{{\sigma }^{2}}}{4Var\left( {{\beta }_{i}} \right)}\,\! }[/math]
The non-centrality parameter for each interaction effect is calculated by:
- [math]\displaystyle{ {{\phi }_{ij}}=\frac{\beta _{ij}^{2}}{Var\left( {{\beta }_{ij}} \right)}=\frac{{{\left( 0.5\Delta \right)}^{2}}}{Var\left( {{\beta }_{ij}} \right)}=\frac{{{\sigma }^{2}}}{4Var\left( {{\beta }_{ij}} \right)}\,\! }[/math]
The non-centrality parameter for each quadratic effect is calculated by:
- [math]\displaystyle{ {{\phi }_{ii}}=\frac{\beta _{ii}^{2}}{Var\left( {{\beta }_{ii}} \right)}=\frac{{{\left( \Delta \right)}^{2}}}{Var\left( {{\beta }_{ii}} \right)}=\frac{{{\sigma }^{2}}}{Var\left( {{\beta }_{ii}} \right)}\,\! }[/math]
All the non-centrality parameters are given in the following table:
Term Non-centrality parameter ([math]\displaystyle{ \phi \,\! }[/math]) A 6.828362 B 6.828362 C 6.828362 AB 4 AC 4 BC 4 AA 28.80018 BB 28.80018 CC 28.80018
The power for each term is calculated by:
- [math]\displaystyle{ Power=1-{{F}_{1,27}}\left( {{f}_{critical}}|{{\phi }_{i}} \right)\,\! }[/math]
They are:
Source Power ([math]\displaystyle{ \Delta =1\sigma \,\! }[/math]) A:A 0.712033 B:B 0.712033 C:C 0.712033 AB 0.487574 AC 0.487574 BC 0.487574 AA 0.999331 BB 0.999331 CC 0.999331
The results in a DOE folio can be obtained from the design evaluation.

Discussion on Power Calculation
All the above examples show how to calculate the power for a given amount of effect.When a power value is given, using the above method we also can calculate the corresponding effect. If the power is too low for an effect of interest, the sample size of the experiment must be increased in order to get a higher power value.
We discussed in detail how to define an “effect” for quantitative and qualitative factors, and how to use model coefficients to represent a given effect. The power in a DOE folio is calculated based on this definition. Readers may find that power is calculated directly based on model coefficients (instead of the contrasts) in other software packages or books. However, for some cases, such as for the main and interaction effects of qualitative factors with multiple levels, the meaning of model coefficients is not very straightforward. Therefore, it is better to use the defined effect (or contrast) shown here to calculate the power, even though this calculation is much more complicated.
Conclusion
In this chapter, we discussed how to evaluate an experiment design. Although the evaluation can be conducted either before or after conducting the experiment, it is always recommended to evaluate an experiment before performing it. A bad design will waste time and money. Readers should check the alias structure, the orthogonality and the power for important effects for an experiment before the tests.