Using Maintenance Tasks

Using Maintenance Tasks
One of the most important benefits of simulation is the ability to define how and when actions are performed. In our case, the actions of interest are part repairs/replacements. This is accomplished in BlockSim through the use of maintenance tasks. Specifically, four different types of tasks can be defined for maintenance actions: corrective maintenance, preventive maintenance, on condition maintenance and inspection.
Corrective Maintenance Tasks
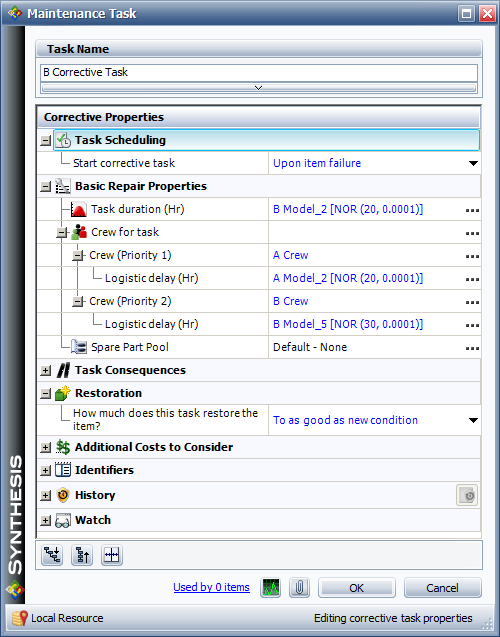
A corrective maintenance task defines when a corrective maintenance (CM) action is performed. The figure below shows a corrective maintenance task assigned to a block in BlockSim. Corrective actions will be performed either immediately upon failure of the item or upon finding that the item has failed (for hidden failures that are not detected until an inspection). BlockSim allows the selection of either category.
- Upon item failure: The CM action is initiated immediately upon failure. If the user doesn't specify the choice for a CM, then this is the default option. All prior examples were based on the instruction to perform a CM upon failure.
- When found failed during an Inspection: The CM action will only be initiated after an inspection is done on the failed component. How and when the inspections are performed is defined by the block's inspection properties. This has the effect of defining a dependency between the corrective maintenance task and the inspection task.
Scheduled Tasks
Scheduled tasks can be performed on a known schedule, which can be based on any of the following:
- A time interval, either fixed or dynamic, based on the item's age (item clock) or on calendar time (system clock). See Item and System Ages.
- The occurrence of certain events, including:
- The system goes down.
- Certain events happen in a maintenance group. The events and groups are user-specified, and the item that the task is assigned to does not need to be part of the selected maintenance group(s).
The types of scheduled tasks include:
- Inspection tasks
- Preventive maintenance tasks
- On condition tasks
Item and System Ages
It is important to keep in mind that the system and each component of the system maintain separate clocks within the simulation. When setting intervals to perform a scheduled task, the intervals can be based on either type of clock. Specifically:
- Item age refers to the accumulated age of the block, which gets adjusted each time the block is repaired (i.e., restored). If the block is repaired at least once during the simulation, this will be different from the elapsed simulation time. For example, if the restoration factor is 1 (i.e., “as good as new”) and the assigned interval is 100 days based on item age, then the task will be scheduled to be performed for the first time at 100 days of elapsed simulation time. However, if the block fails at 85 days and it takes 5 days to complete the repair, then the block will be fully restored at 90 days and its accumulated age will be reset to 0 at that point. Therefore, if another failure does not occur in the meantime, the task will be performed for the first time 100 days later at 190 days of elapsed simulation time.

- Calendar time refers to the elapsed simulation time. If the assigned interval is 100 days based on calendar time, then the task will be performed for the first time at 100 days of elapsed simulation time, for the second time at 200 days of elapsed simulation time and so on, regardless of whether the block fails and gets repaired correctively between those times.

Inspection Tasks
Like all scheduled tasks, inspections can be performed based on a time interval or upon certain events. Inspections can be specified to bring the item or system down or not.
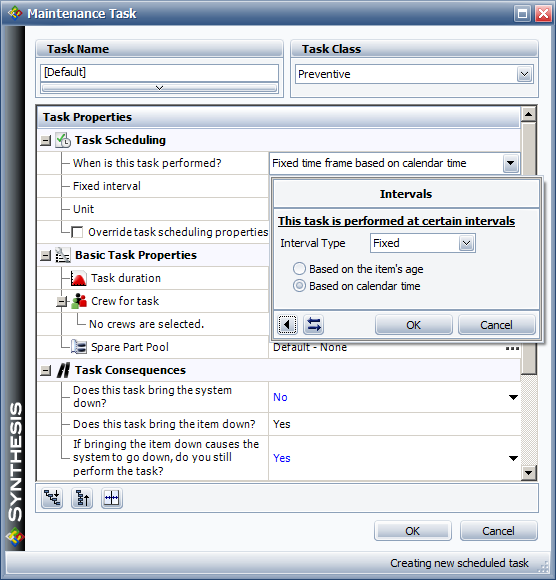
Preventive Maintenance Tasks
The figure below shows the options available in a preventive maintenance (PM) task within BlockSim. PMs can be performed based on a time interval or upon certain events. Because PM tasks always bring the item down, one can also specify whether preventive maintenance will be performed if the task brings the system down.
On Condition Tasks
On condition maintenance relies on the capability to detect failures before they happen so that preventive maintenance can be initiated. If, during an inspection, maintenance personnel can find evidence that the equipment is approaching the end of its life, then it may be possible to delay the failure, prevent it from happening or replace the equipment at the earliest convenience rather then allowing the failure to occur and possibly cause severe consequences. In BlockSim, on condition tasks consist of an inspection task that triggers a preventive task when an impending failure is detected during inspection.
Failure Detection
Inspection tasks can be used to check for indications of an approaching failure. BlockSim models such indications of when an approaching failure will become detectable upon inspection using Failure Detection Threshold and P-F Interval. Failure detection threshold allows the user to enter a number between 0 and 1 indicating the percentage of an item's life that must elapse before an approaching failure can be detected. For instance, if the failure detection threshold value is set as 0.8 then this means that the failure of a component can be detected only during the last 20% of its life. If an inspection occurs during this time, an approaching failure is detected and the inspection triggers a preventive maintenance task to take the necessary precautions to delay the failure by either repairing or replacing the component.
The P-F interval allows the user to enter the amount of time before the failure of a component when the approaching failure can be detected by an inspection. The P-F interval represents the warning period that spans from P(when a potential failure can be detected) to F(when the failure occurs). If a P-F interval is set as 200 hours, then the approaching failure of the component can only be detected at 200 hours before the failure of the component. Thus, if a component has a fixed life of 1,000 hours and the P-F interval is set to 200 hours, then if an inspection occurs at or beyond 800 hours, then the approaching failure of the component that is to occur at 1,000 hours is detected by this inspection and a preventive maintenance task is triggered to take action against this failure.
Rules for On Condition Tasks
- An inspection that finds a block at or beyond the failure detection threshold or within the range of the P-F interval will trigger the associated preventive task as long as preventive maintenance can be performed on that block.
- If a non-downing inspection triggers a preventive maintenance action because the failure detection threshold or P-F interval range was reached, no other maintenance task will be performed between the inspection and the triggered preventive task; tasks that would otherwise have happened at that time due to system age, system down or group maintenance will be ignored.
- A preventive task that would have been triggered by a non-downing inspection will not happen if the block fails during the inspection, as corrective maintenance will take place instead.
- If a failure will occur within the failure detection threshold or P-F interval set for the inspection, but the preventive task is only supposed to be performed when the system is down, the simulation waits until the requirements of the preventive task are met to perform the preventive maintenance.
- If the on condition inspection triggers the preventive maintenance part of the task, the simulation assumes that the maintenance crew will forego any routine servicing associated with the inspection part of the task. In other words, the restoration will come from the preventive maintenance, so any restoration factor defined for the inspection will be ignored in these circumstances.
Example Using P-F Interval
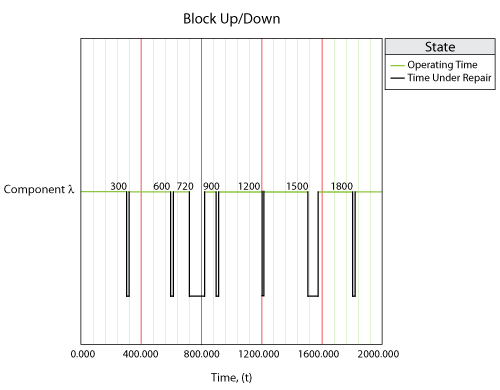
To illustrate the use of the P-F interval in BlockSim, consider a component [math]\displaystyle{ A\,\! }[/math] that fails every 700 [math]\displaystyle{ tu\,\! }[/math]. The corrective maintenance on this equipment takes 100 [math]\displaystyle{ tu\,\! }[/math] to complete, while the preventive maintenance takes 50 [math]\displaystyle{ tu\,\! }[/math] to complete. Both the corrective and preventive maintenance actions have a type II restoration factor of 1. Inspection tasks of 10 [math]\displaystyle{ tu\,\! }[/math] duration are performed on the component every 300 [math]\displaystyle{ tu\,\! }[/math]. There is no restoration of the component during the inspections. The P-F interval for this component is 100 [math]\displaystyle{ tu\,\! }[/math].
The component behavior from 0 to 2000 [math]\displaystyle{ tu\,\! }[/math] is shown in the figure below and described next.
- At 300 [math]\displaystyle{ tu\,\! }[/math] the first scheduled inspection of 10 [math]\displaystyle{ tu\,\! }[/math] duration occurs. At this time the age of the component is 300 [math]\displaystyle{ tu\,\! }[/math]. This inspection does not lie in the P-F interval of 100 [math]\displaystyle{ tu\,\! }[/math] (which begins at the age of 600 [math]\displaystyle{ tu\,\! }[/math] and ends at the age of 700 [math]\displaystyle{ tu\,\! }[/math]). Thus, no approaching failure is detected during this inspection.
- At 600 [math]\displaystyle{ tu\,\! }[/math] the second scheduled inspection of 10 [math]\displaystyle{ tu\,\! }[/math] duration occurs. At this time the age of the component is 590 [math]\displaystyle{ tu\,\! }[/math] (no age is accumulated during the first inspection from 300 tu to 310 [math]\displaystyle{ tu\,\! }[/math] as the component does not operate during this inspection). Again this inspection does not lie in the P-F interval. Thus, no approaching failure is detected during this inspection.
- At 720 [math]\displaystyle{ tu\,\! }[/math] the component fails after having accumulated an age of 700 [math]\displaystyle{ tu\,\! }[/math]. A corrective maintenance task of 100 [math]\displaystyle{ tu\,\! }[/math] duration occurs to restore the component to as-good-as-new condition.
- At 900 [math]\displaystyle{ tu\,\! }[/math] the third scheduled inspection occurs. At this time the age of the component is 80 [math]\displaystyle{ tu\,\! }[/math]. This inspection does not lie in the P-F interval (from age 600 [math]\displaystyle{ tu\,\! }[/math] to 700 [math]\displaystyle{ tu\,\! }[/math]). Thus, no approaching failure is detected during this inspection.
- At 1200 [math]\displaystyle{ tu\,\! }[/math] the fourth scheduled inspection occurs. At this time the age of the component is 370 [math]\displaystyle{ tu\,\! }[/math]. Again, this inspection does not lie in the P-F interval and no approaching failure is detected.
- At 1500 [math]\displaystyle{ tu\,\! }[/math] the fifth scheduled inspection occurs. At this time the age of the component is 660 [math]\displaystyle{ tu\,\! }[/math], which lies in the P-F interval. As a result, an approaching failure is detected and the inspection triggers a preventive maintenance task. A preventive maintenance task of 50 [math]\displaystyle{ tu\,\! }[/math] duration occurs at 1510 [math]\displaystyle{ tu\,\! }[/math] to restore the component to as-good-as-new condition.
- At 1800 [math]\displaystyle{ tu\,\! }[/math] the sixth scheduled inspection occurs. At this time the age of the component is 240 [math]\displaystyle{ tu\,\! }[/math]. This inspection does not lie in the P-F interval (from age 600 tu to 700 [math]\displaystyle{ tu\,\! }[/math]) and no approaching failure is detected.
Rules for PMs and Inspections
All the options available in the Maintenance task window were designed to maximize the modeling flexibility within BlockSim. However, maximizing the modeling flexibility introduces issues that you need to be aware of and requires you to carefully select options in order to assure that the selections do not contradict one another. One obvious case would be to define a PM action on a component in series (which will always bring the system down) and then assign a PM policy to the block that has the Do not perform maintenance if the action brings the system down option set. With these settings, no PMs will ever be performed on the component during the BlockSim simulation. The following sections summarize some issues and special cases to consider when defining maintenance properties in BlockSim.
- Inspections do not consume spare parts. However, an inspection can have a renewal effect on the component if the restoration factor is set to a number other than the default of 0.
- On the inspection tab, if Inspection brings system down is selected, this also implies that the inspection brings the item down.
- If a PM or an inspection are scheduled based on the item's age, then they will occur exactly when the item reaches that age. However, it is important to note that failed items do not age. Thus, if an item fails before it reaches that age, the action will not be performed. This means that if the item fails before the scheduled inspection (based on item age) and the CM is set to be performed upon inspection, the CM will never take place. The reason that this option is allowed in BlockSim is for the flexibility of specifying renewing inspections.
- Downtime due to a failure discovered during a non-downing inspection is included when computing results "w/o PM, OC & Inspections."
- If a PM upon item age is scheduled and is not performed because it brings the system down (based on the option in the PM task) the PM will not happen unless the item reaches that age again (after restoration by CM, inspection or another type of PM).
- If the CM task is upon inspection and a failed component is scheduled for PM prior to the inspection, the PM action will restore the component and the CM will not take place.
- In the case of simultaneous events, only one event is executed (except the case in maintenance phase, in maintenance phase, all simultaneous events in maintenance phase are executed in a order). The following precedence order is used: 1). Tasks based on intervals or upon start of a maintenance phase; 2). Tasks based on events in a maintenance group, where the triggering event applies to a block; 3). Tasks based on system down; 4). Tasked on events in a maintenance group, where the triggering event applies to a subdiagram. Within these categories, order is determined according to the priorities specified in the URD (i.e., the higher the task in on the list, the higher the priority).
- The PM option of Do not perform if it brings the system down is only considered at the time that the PM needs to be initiated. If the system is down at that time, due to another item, then the PM will be performed regardless of any future consequences to the system up state. In other words, when the other item is fixed, it is possible that the system will remain down due to this PM action. In this case, the PM time difference is added to the system PM downtime.
- Downing events cannot overlap. If a component is down due to a PM and another PM is suggested based on another trigger, the second call is ignored.
- A non-downing inspection with a restoration factor restores the block based on the age of the block at the beginning of the inspection (i.e., duration is not restored).
- Non-downing events can overlap with downing events. If in a non-downing inspection and a downing event happen concurrently, the non-downing event will be managed in parallel with the downing event.
- If a failure or PM occurs during a non-downing inspection and the CM or PM has a restoration factor and the inspection action has a restoration factor, then both restoration factors are used (compounded).
- A PM or inspection on system down is triggered only if the system was up at the time that the event brought the system down.
- A non-downing inspection with restoration factor of 0 does not affect the block.
Example
To illustrate the use of maintenance policies in BlockSim we will use the same example from Example Using Both Crews and Pools with the following modifications (The figures below also show these settings):
Blocks A and D:
- Belong to the same group (Group 1).
- Corrective maintenance actions are upon inspection (not upon failure) and the inspections are performed every 30 hours, based on system time. Inspections have a duration of 1 hour. Furthermore, unlimited free crews are available to perform the inspections.
- Whenever either item get CM, the other one gets a PM.
- The PM has a fixed duration of 10 hours.
- The same crews are used for both corrective and preventive maintenance actions.



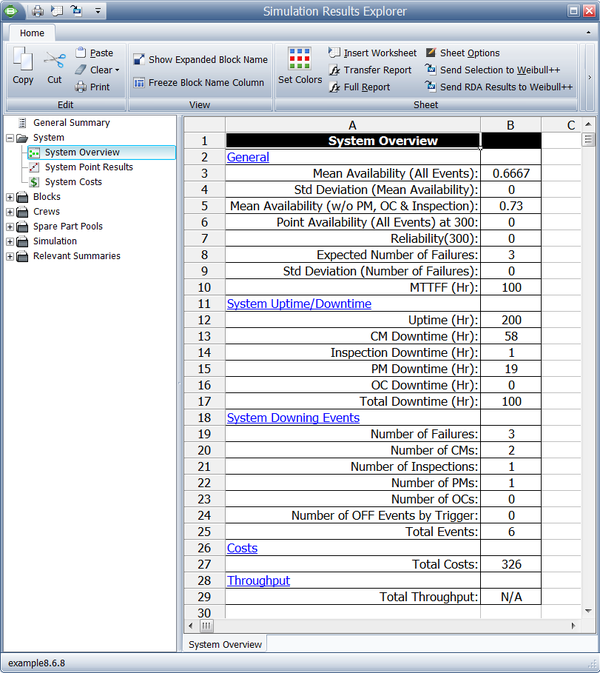
System Overview
The item and system behavior from 0 to 300 hours is shown in the figure below and described next.
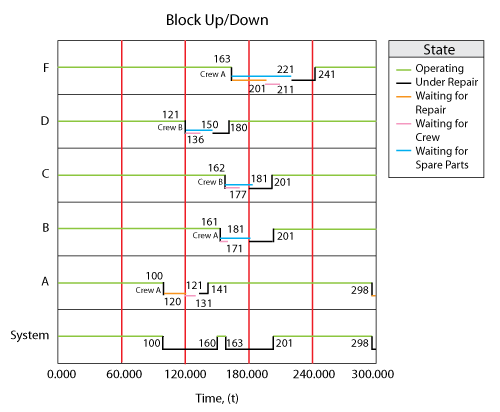
- 1. At 100, block [math]\displaystyle{ A\,\! }[/math] goes down and brings the system down.
- a) No maintenance action is performed since an upon inspection policy was used.
- b) The next scheduled inspection is at 120, thus Crew [math]\displaystyle{ A\,\! }[/math] is called to perform the maintenance by 121 (end of the inspection).
- 2. Crew [math]\displaystyle{ A\,\! }[/math] arrives and initiates the repair on [math]\displaystyle{ A\,\! }[/math] at 131.
- a) The only part in the pool is used and an on-condition restock is triggered.
- b) Pool [on-hand = 0, pending: 150 [math]\displaystyle{ _{s}\,\! }[/math], 181].
- c) Block [math]\displaystyle{ A\,\! }[/math] is repaired by 141.
- 3. At the same time (121), a PM is initiated for block [math]\displaystyle{ D\,\! }[/math] because the PM task called for "PM upon the start of corrective maintenance on another group item."
- a) Crew [math]\displaystyle{ B\,\! }[/math] is called for block [math]\displaystyle{ D\,\! }[/math] and arrives at 136.
- b) No part is available until 150. An on-condition restock is triggered for 181.
- c) Pool [on-hand = 0, pending: 150 [math]\displaystyle{ _{s}\,\! }[/math], 181, 181].
- d) At 150, a part becomes available and the PM is completed by 160.
- e) Pool [on-hand = 0, pending: 181, 181].
- 4. At 161, block [math]\displaystyle{ B\,\! }[/math] fails (corrective maintenance upon failure).
- a) Block [math]\displaystyle{ B\,\! }[/math] gets Crew [math]\displaystyle{ A\,\! }[/math], which arrives at 171.
- b) No part is available until 181. An on-condition restock is triggered for 221.
- c) Pool [on-hand = 0, pending: 181, 181, 221].
- d) A part arrives at 181.
- e) The repair is completed by 201.
- f) Pool [on-hand = 0, pending: 181, 221].
- 5. At 162, block [math]\displaystyle{ C\,\! }[/math] fails.
- a) Block [math]\displaystyle{ C\,\! }[/math] gets Crew [math]\displaystyle{ B\,\! }[/math], which arrives at 177.
- b) No part is available until 181. An on-condition restock is triggered for 222.
- c) Pool [on-hand = 0, pending: 181, 221, 222].
- d) A part arrives at 181.
- e) The repair is completed by 201.
- f) Pool [on-hand = 0, pending: 221, 222].
- 6. At 163, block [math]\displaystyle{ F\,\! }[/math] fails and brings the system down.
- a) Block [math]\displaystyle{ F\,\! }[/math] calls Crew [math]\displaystyle{ A\,\! }[/math] then [math]\displaystyle{ B\,\! }[/math]. Both are busy.
- b) Crew [math]\displaystyle{ A\,\! }[/math] will be the first available so .. calls [math]\displaystyle{ A\,\! }[/math] again and waits.
- c) No part is available until 221. An on-condition restock is triggered for 223.
- d) Pool [on-hand = 0, pending: 221, 222, 223].
- e) Crew [math]\displaystyle{ A\,\! }[/math] arrives at 211.
- f) Repair begins at 221.
- g) Repair is completed by 241.
- h) Pool [on-hand = 0, pending: 222, 223].
- 7. At 298, block [math]\displaystyle{ A\,\! }[/math] goes down and brings the system down.
- 1. At 100, block [math]\displaystyle{ A\,\! }[/math] goes down and brings the system down.
System Uptimes/Downtimes
- 1. Uptime: This is 200 hours.
- a) This can be obtained by observing the following system up durations: 0 to 100, 160 to 163 and 201 to 298.
- 2. CM Downtime: This is 58 hours.
- a) Observe that even though the system failed at 100, the CM action (on block [math]\displaystyle{ A\,\! }[/math] ) was initiated at 121 and lasted until 141, thus only 20 hours of this downtime are attributed to the CM action.
- b) The next CM action started at 163 when block [math]\displaystyle{ F\,\! }[/math] failed and lasted until 201 when blocks [math]\displaystyle{ B\,\! }[/math] and [math]\displaystyle{ C\,\! }[/math] were restored, thus adding another 38 hours of CM downtime.
- 3. Inspection Downtime: This is 1 hour.
- a) The only time the system was under inspection was from 120 to 121, during the inspection of block [math]\displaystyle{ A\,\! }[/math].
- 4. PM Downtime: This is 19 hours.
- a) Note that the entire PM action duration on block [math]\displaystyle{ D\,\! }[/math] was from 121 to 160.
- b) Until 141, and from the system perspective, the CM on block [math]\displaystyle{ A\,\! }[/math] was the cause for the downing. Once block [math]\displaystyle{ A\,\! }[/math] was restored (at 141), then the reason for the system being down became the PM on block [math]\displaystyle{ D\,\! }[/math].
- c) Thus, the PM on block [math]\displaystyle{ D\,\! }[/math] was only responsible for the downtime after block [math]\displaystyle{ A\,\! }[/math] was restored, or from 141 to 160.
- 5. OC Downtime: This is 0. There is not on condition task in this example.
- 6. Total Downtime: This is 100 hours.
- a) This includes all of the above downtimes plus the 20 hours (100 to 120) and the 2 hours (298 to 300) that the system was down due the undiscovered failure of block [math]\displaystyle{ A\,\! }[/math].
- 1. Uptime: This is 200 hours.
System Metrics
- 1. Mean Availability (All Events):
- [math]\displaystyle{ \frac{300-100}{300}=0.6667\,\! }[/math]
- 2. Mean Availability (w/o PM & Inspection):
- a) This is due to the CM downtime of 58, the undiscovered downtime of 22 and the inspection downtime of 1, or:
- [math]\displaystyle{ \frac{300-(58+22+1)}{300}=0.7333\,\! }[/math]
- b) It should be noted that the inspection downtime was included even though the definition was "w/o PM & Inspection." The reason for this is that the inspection did not cause the downtime in this case. Only downtimes caused by the PM or inspections are excluded.
- 3. Point Availability and Reliability at 300 is zero because the system was down at 300.
- 4. Expected Number of Failures is 3.
- a) The system failed at 100, 163 and 298.
- 5. The standard deviation of the number of failures is 0.
- 6. The MTTFF is 100 because the example is deterministic.
The System Downing Events
- 1. Number of Failures is 3.
- a) The first is the failure of block [math]\displaystyle{ A\,\! }[/math], the second is the failure of block [math]\displaystyle{ F\,\! }[/math] and the third is the failure of block [math]\displaystyle{ A\,\! }[/math].
- 2. Number of CMs is 2.
- a) The first is the CM on block [math]\displaystyle{ A\,\! }[/math] and the second is the CM on block [math]\displaystyle{ F\,\! }[/math].
- 3. Number of Inspections is 1.
- 4. Number of PMs is 1.
- 5. Total Events are 6. These are events that the downtime can be attributed to. Specifically, the following events were observed:
- a) The failure of block [math]\displaystyle{ A\,\! }[/math] at 100.
- b) Inspection on block [math]\displaystyle{ A\,\! }[/math] at 120.
- c) The CM action on block [math]\displaystyle{ A\,\! }[/math].
- d) The PM action on block [math]\displaystyle{ D\,\! }[/math] (after [math]\displaystyle{ A\,\! }[/math] was fixed).
- e) The failure of block [math]\displaystyle{ F\,\! }[/math] at 163.
- f) The failure of block [math]\displaystyle{ A\,\! }[/math] at 298.
- 1. Number of Failures is 3.
Block Details
The details for blocks [math]\displaystyle{ A,B,C,D\,\! }[/math] and [math]\displaystyle{ F\,\! }[/math] are shown below.

We will discuss some of these results. First note that there are four downing events on block [math]\displaystyle{ A\,\! }[/math] : initial failure, inspection and CM, plus the last failure at 298. All others have just one. Also, block [math]\displaystyle{ A\,\! }[/math] had a total downtime of [math]\displaystyle{ 41+2\,\! }[/math], giving it a mean availability of 0.8567. The first time-to-failure for block [math]\displaystyle{ A\,\! }[/math] occurred at 100 while the second occurred after [math]\displaystyle{ 298-141=157\,\! }[/math] hours of operation, yielding an average time between failures (MTBF) of [math]\displaystyle{ 257/2=128.5\,\! }[/math]. (Note that this is the same as uptime/failures.) Block [math]\displaystyle{ D\,\! }[/math] never failed, so its MTBF cannot be determined. Furthermore, MTBDE for each item is determined by dividing the block's uptime by the number of events. The RS FCI and RS DECI metrics are obtained by looking at the SD Failures and SD Events of the item and the number of system failures and events. Specifically, the only items that caused system failure are blocks [math]\displaystyle{ A\,\! }[/math] and [math]\displaystyle{ F\,\! }[/math] ; [math]\displaystyle{ A\,\! }[/math] at 100 and 298 and [math]\displaystyle{ F\,\! }[/math] at 163. It is important to note that even though one could argue that block [math]\displaystyle{ F\,\! }[/math] alone did not cause the failure ( [math]\displaystyle{ B\,\! }[/math] and [math]\displaystyle{ C\,\! }[/math] were also failed), the downing was attributed to [math]\displaystyle{ F\,\! }[/math] because the system reached a failed state only when block [math]\displaystyle{ F\,\! }[/math] failed.
On the number of inspections, which were scheduled every 30 hours, nine occurred for block [math]\displaystyle{ A\,\! }[/math] [30, 60, 90, 120, 150, 180, 210, 240, 270] and eight for block [math]\displaystyle{ D\,\! }[/math]. Block [math]\displaystyle{ D\,\! }[/math] did not get inspected at 150 because block [math]\displaystyle{ D\,\! }[/math] was undergoing a PM action at that time.
Crew Details
The figure below shows the crew results.

Crew [math]\displaystyle{ A\,\! }[/math] received a total of six calls and accepted three. Specifically,
- At 121, the crew was called by block [math]\displaystyle{ A\,\! }[/math] and the call was accepted.
- At 121, block [math]\displaystyle{ D\,\! }[/math] also called for its PM action and was rejected. Block [math]\displaystyle{ D\,\! }[/math] then called crew [math]\displaystyle{ B\,\! }[/math], which accepted the call.
- At 161, block [math]\displaystyle{ B\,\! }[/math] called crew [math]\displaystyle{ A\,\! }[/math]. Crew [math]\displaystyle{ A\,\! }[/math] accepted.
- At 162, block [math]\displaystyle{ C\,\! }[/math] called crew [math]\displaystyle{ A\,\! }[/math]. Crew [math]\displaystyle{ A\,\! }[/math] rejected and block [math]\displaystyle{ C\,\! }[/math] called crew [math]\displaystyle{ B\,\! }[/math], which accepted the call.
- At 163, block [math]\displaystyle{ F\,\! }[/math] called crew [math]\displaystyle{ A\,\! }[/math] and then crew [math]\displaystyle{ B\,\! }[/math] and both rejected. Block [math]\displaystyle{ F\,\! }[/math] then waited until a crew became available at 201 and called that crew again. This was crew [math]\displaystyle{ A\,\! }[/math], which accepted.
The total wait time is the time that blocks had to wait for the maintenance crew. Block [math]\displaystyle{ F\,\! }[/math] is the only component that waited, waiting 38 hours for crew [math]\displaystyle{ A\,\! }[/math].
Also, the costs for crew [math]\displaystyle{ A\,\! }[/math] were 1 per unit time and 10 per incident, thus the total costs were 100 + 30. The costs for Crew [math]\displaystyle{ B\,\! }[/math] were 2 per unit time and 20 per incident, thus the total costs were 156 + 40.
Pool Details
The figure below shows the spare part pool results.

The pool started with a stock level of 1 and ended up with 2. Specifically,
- At 121, the pool dispensed a part to block [math]\displaystyle{ A\,\! }[/math] and ordered another to arrive at 181.
- At 121, it dispensed a part to block [math]\displaystyle{ D\,\! }[/math] and ordered another to arrive at 181.
- At 150, a scheduled part arrived to restock the pool.
- At 161 the pool dispensed a part to block [math]\displaystyle{ B\,\! }[/math] and ordered another to arrive at 221.
- At 181, it dispensed a part to block [math]\displaystyle{ C\,\! }[/math] and ordered another to arrive at 222.
- At 221, it dispensed a part to block [math]\displaystyle{ F\,\! }[/math] and ordered another to arrive at 223.
- The 222 and 223 arrivals remained in stock until the end of the simulation.
Overall, five parts were dispensed. Blocks had to wait a total of 126 hours to receive parts (B: 181-161=20, C: 181-162=19, D: 150-121=29 and F: 221-163=58).